代数的型のサイズとドメインモデリング
この記事では、代数的型の「サイズ」、つまり集合で言う濃度の計算方法と、この知識が設計の決定にどう役立つかを見ていきます。
型の「サイズ」を定義するために、それを集合と考え、可能な要素の数を数えます。
たとえば、可能なブール値は2つなので、Boolean型のサイズは2です。
サイズが1の型はあるでしょうか?はい、unit型にはただ1つの値しかありません。それは()です。
サイズが0の型はあるでしょうか?つまり、値が全くない型は存在するでしょうか?F#にはありませんが、Haskellにはあります。それはVoidと呼ばれます。
次のような型ではどうでしょうか。
type ThreeState = | Checked | Unchecked | Unknownこのサイズはいくつでしょうか?可能な値は3つなので、サイズは3です。
次のような型はどうでしょうか。
type Direction = | North | East | South | West明らかに4です。
これでお分かりいただけたと思います!
複合型のサイズの計算
Section titled “複合型のサイズの計算”ここで、複合型のサイズの計算を見ていきましょう。「F# の型を理解する」シリーズを思い出してほしいのですが、代数的型には2種類あります。 タプルやレコードなどの「積」型と、F#では判別共用体と呼ばれる「和」型です。
たとえば、SpeedとDirectionがあり、それらをVelocityというレコード型に組み合わせるとします。
type Speed = | Slow | Fast
type Velocity = { direction: Direction speed: Speed }Velocityのサイズはいくつでしょうか?
可能な値をすべて書き出すと以下のようになります。
{direction=North; speed=Slow}; {direction=North; speed=Fast}{direction=East; speed=Slow}; {direction=East; speed=Fast}{direction=South; speed=Slow}; {direction=South; speed=Fast}{direction=West; speed=Slow}; {direction=West; speed=Fast}可能な値は8つあり、2つのSpeed値と4つのDirection値のすべての組み合わせに対応しています。
これを一般化してルールにすると次のようになります。
- ルール:直積型のサイズは、構成要素の型のサイズの積です。
つまり、次のようなレコード型があるとします。
type RecordType = { a : TypeA b : TypeB }サイズは次のように計算されます。
size(RecordType) = size(TypeA) * size(TypeB)同様に、タプルの場合も
type TupleType = TypeA * TypeBサイズはこのようになります。
size(TupleType) = size(TypeA) * size(TypeB)直和型も同じように分析できます。次のように定義されたMovement型があるとします。
type Movement = | Moving of Direction | NotMoving可能性をすべて書き出して数えると
Moving NorthMoving EastMoving SouthMoving WestNotMoving合計で5つです。これは偶然にもsize(Direction) + 1になります。こちらも面白い例です。
type ThingsYouCanSay = | Yes | Stop | Goodbye
type ThingsICanSay = | No | GoGoGo | Hello
type HelloGoodbye = | YouSay of ThingsYouCanSay | ISay of ThingsICanSayここでも、可能性をすべて書き出して数えてみましょう。
YouSay YesISay NoYouSay StopISay GoGoGoYouSay GoodbyeISay HelloYouSayケースで3つの可能な値があり、ISayケースでも3つの可能な値があるので、合計6つになります。
ここでも、一般的なルールを作ることができます。
- ルール:直和型または共用体型のサイズは、構成要素の型のサイズの和です。
つまり、次のような共用体型があるとします。
type SumType = | CaseA of TypeA | CaseB of TypeBサイズは次のように計算されます。
size(SumType) = size(TypeA) + size(TypeB)ジェネリック型の扱い
Section titled “ジェネリック型の扱い”ジェネリック型を加えるとどうなるでしょうか?
たとえば、次のような型のサイズはどうでしょうか。
type Optional<'a> = | Something of 'a | Nothingまず言えることは、Optional<'a>は「型」ではなく「型コンストラクタ」だということです。Optional<string>は型です。Optional<int>も型ですが、Optional<'a>は型ではありません。
それでも、size(Optional<string>)がsize(string) + 1、Optional<int>がsize(int) + 1となることに注目すれば、サイズを計算できます。
つまり、次のように言えます。
size(Optional<'a>) = size('a) + 1同様に、次のような2つのジェネリックを持つ型の場合
type Either<'a,'b> = | Left of 'a | Right of 'bそのサイズは、ジェネリック構成要素のサイズを使って計算できます(上記の「和のルール」を使用)。
size(Either<'a,'b>) = size('a) + size('b)再帰型はどうでしょうか?最も単純なものとして、連結リストを見てみましょう。
連結リストは空か、タプルを持つセルがあります。先頭は'aで、末尾は別のリストです。定義は次のようになります。
type LinkedList<'a> = | Empty | Node of head:'a * tail:LinkedList<'a>サイズを計算するために、各構成要素に名前をつけましょう。
let S = size(LinkedList<'a>)let N = size('a)これで次のように書けます。
S = 1 // "Empty"ケースのサイズ + // 共用体型 N * S // タプルサイズ計算を使用した"Cell"ケースのサイズこの式で少し遊んでみましょう。まず
S = 1 + (N * S)から始めて、最後のSを式で置き換えると
S = 1 + (N * (1 + (N * S)))整理すると
S = 1 + N + (N^2 * S)(ここでN^2は「Nの2乗」を意味します)
再び最後のSを式で置き換えると
S = 1 + N + (N^2 * (1 + (N * S)))さらに整理すると
S = 1 + N + N^2 + (N^3 * S)このパターンが見えてきましたね!Sの式は無限に展開できます。
S = 1 + N + N^2 + N^3 + N^4 + N^5 + ...これをどう解釈すればいいでしょうか?リストは次のケースの和だと言えます。
- 空のリスト(サイズ = 1)
- 1要素のリスト(サイズ = N)
- 2要素のリスト(サイズ = N x N)
- 3要素のリスト(サイズ = N x N x N)
- 以下同様
この式がそれを表現しています。
余談ですが、S = 1/(1-N)という式を使ってSを直接計算できます。これはDirection(サイズ=4)のリストのサイズが「-1/3」になることを意味します。
うーん、変ですね!これはこの「-1/12」の動画を思い出させます。
関数のサイズの計算
Section titled “関数のサイズの計算”関数はどうでしょうか?サイズを計算できるでしょうか?
もちろん、可能な実装をすべて書き出して数えるだけです。簡単ですね!
たとえば、カードのSuit(スート)をColor(色)に対応させるSuitColor関数があるとします。
type Suit = Heart | Spade | Diamond | Clubtype Color = Red | Black
type SuitColor = Suit -> Color1つの実装は、どのスートが与えられても赤を返すものです。
(Heart -> Red); (Spade -> Red); (Diamond -> Red); (Club -> Red)別の実装は、Club以外のすべてのスートに対して赤を返すものです。
(Heart -> Red); (Spade -> Red); (Diamond -> Red); (Club -> Black)実際、この関数の可能な実装をすべて書き出すと16通りあります。
(Heart -> Red); (Spade -> Red); (Diamond -> Red); (Club -> Red)(Heart -> Red); (Spade -> Red); (Diamond -> Red); (Club -> Black)(Heart -> Red); (Spade -> Red); (Diamond -> Black); (Club -> Red)(Heart -> Red); (Spade -> Red); (Diamond -> Black); (Club -> Black)
(Heart -> Red); (Spade -> Black); (Diamond -> Red); (Club -> Red)(Heart -> Red); (Spade -> Black); (Diamond -> Red); (Club -> Black) // 正しいもの!(Heart -> Red); (Spade -> Black); (Diamond -> Black); (Club -> Red)(Heart -> Red); (Spade -> Black); (Diamond -> Black); (Club -> Black)
(Heart -> Black); (Spade -> Red); (Diamond -> Red); (Club -> Red)(Heart -> Black); (Spade -> Red); (Diamond -> Red); (Club -> Black)(Heart -> Black); (Spade -> Red); (Diamond -> Black); (Club -> Red)(Heart -> Black); (Spade -> Red); (Diamond -> Black); (Club -> Black)
(Heart -> Black); (Spade -> Black); (Diamond -> Red); (Club -> Red)(Heart -> Black); (Spade -> Black); (Diamond -> Red); (Club -> Black)(Heart -> Black); (Spade -> Black); (Diamond -> Black); (Club -> Red)(Heart -> Black); (Spade -> Black); (Diamond -> Black); (Club -> Black)別の見方をすると、各値が特定の実装を表すレコード型を定義できます。
Heart入力に対してどの色を返すか、Spade入力に対してどの色を返すか、といった具合です。
SuitColorの実装の型定義は次のようになります。
type SuitColorImplementation = { Heart : Color Spade : Color Diamond : Color Club : Color }このレコード型のサイズはいくつでしょうか?
size(SuitColorImplementation) = size(Color) * size(Color) * size(Color) * size(Color)ここには4つのsize(Color)があります。言い換えると、入力ごとに1つのsize(Color)があるので、次のように書けます。
size(SuitColorImplementation) = size(Color)のsize(Suit)乗一般に、次のような関数型があるとします。
type Function<'input,'output> = 'input -> 'output関数のサイズはsize(出力型)のsize(入力型)乗になります。
size(Function) = size(output) ^ size(input)これもルールにしましょう。
- ルール:関数型のサイズは
size(出力型)のsize(入力型)乗です。
さて、これはとても興味深いですが、実用的でしょうか?
私はそう思います。このような型のサイズを理解することは、ある型から別の型への変換を設計する上で役立ちます。これは私たちがよく行うことです!
たとえば、はい/いいえの回答を表す共用体型とレコード型があるとします。
type YesNoUnion = | Yes | No
type YesNoRecord = { isYes: bool }これらの間でどのようにマッピングできるでしょうか?
両方ともサイズは2なので、一方の型の各値を他方の型に対応させることができるはずです。
let toUnion yesNoRecord = if yesNoRecord.isYes then Yes else No
let toRecord yesNoUnion = match yesNoUnion with | Yes -> {isYes = true} | No -> {isYes = false}これは「損失のない」変換と呼べるものです。変換を往復させると、元の値を復元できます。 数学者はこれを同型写像(アイソモーフィズム:ギリシャ語で「同じ形」の意味)と呼びます。
別の例を見てみましょう。はい、いいえ、たぶんの3つのケースを持つ型があります。
type YesNoMaybe = | Yes | No | Maybeこの型を次の型に損失なく変換できるでしょうか?
type YesNoOption = { maybeIsYes: bool option }optionのサイズはいくつでしょうか?内部の型のサイズに1を足したものです。この場合、内部の型はboolです。したがって、YesNoOptionのサイズも3です。
変換関数は次のようになります。
let toYesNoMaybe yesNoOption = match yesNoOption.maybeIsYes with | None -> Maybe | Some b -> if b then Yes else No
let toYesNoOption yesNoMaybe = match yesNoMaybe with | Yes -> {maybeIsYes = Some true} | No -> {maybeIsYes = Some false} | Maybe -> {maybeIsYes = None}ここからルールを作れます。
- ルール:2つの型のサイズが同じであれば、損失のない変換関数のペアを作成できます
試してみましょう。Nibble型とTwoNibbles型があります。
type Nibble = { bit1: bool bit2: bool bit3: bool bit4: bool }
type TwoNibbles = { high: Nibble low: Nibble }TwoNibblesをbyteに、そしてその逆に変換できるでしょうか?
Nibbleのサイズは2 x 2 x 2 x 2 = 16(積のサイズルールを使用)で、TwoNibblesのサイズはsize(Nibble) x size(Nibble)、つまり16 x 16で256です。
したがって、TwoNibblesからbyteへの、そしてその逆の変換が可能です。
損失のある変換
Section titled “損失のある変換”型のサイズが異なる場合はどうなるでしょうか?
目標の型が元の型より「大きい」場合は、常に損失なく変換できます。しかし、目標の型が元の型より「小さい」場合は問題があります。
たとえば、int型はstring型より小さいです。intを正確にstringに変換できますが、stringを簡単にintに変換することはできません。
stringをintにマッピングしたい場合、整数でない文字列の一部を、目標の型の特別な非整数値にマッピングする必要があります。
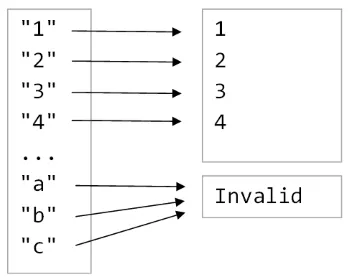
つまり、サイズから、目標の型は単なるint型ではなく、int + 1型でなければならないことがわかります。言い換えると、Option型です!
興味深いことに、BCLのInt32.TryParse関数は2つの値(成功/失敗を示すboolと、パースされた結果のint)を返します。つまり、bool * intというタプルです。
そのタプルのサイズは2 x intで、実際に必要な値よりもはるかに多くなります。Option型の勝利です!
次に、stringをDirectionに変換する場合を考えてみましょう。一部の文字列は有効ですが、ほとんどは無効です。
しかし今回は、1つの無効なケースを持つのではなく、空の入力、長すぎる入力、その他の無効な入力を区別したいとします。
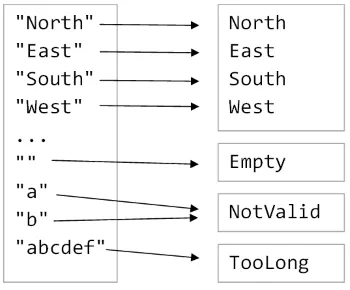
もはやOption型で目標をモデル化することはできないので、7つのケースすべてを含むカスタム型を設計しましょう。
type StringToDirection_V1 = | North | East | South | West | Empty | NotValid | TooLongしかし、この設計は成功した変換と失敗した変換を混在させています。分離してはどうでしょうか?
type Direction = | North | East | South | West
type ConversionFailure = | Empty | NotValid | TooLong
type StringToDirection_V2 = | Success of Direction | Failure of ConversionFailureStringToDirection_V2のサイズはいくつでしょうか?
Successケースには4つのDirectionの選択肢があり、Failureケースには3つのConversionFailureの選択肢があるので、
合計サイズは7で、最初のバージョンと同じです。
つまり、これらの設計は「等価」で、どちらも使えるということです。
個人的には、バージョン2を好みますが、レガシーコードにバージョン1があっても、バージョン1からバージョン2へ、そしてその逆へ損失なく変換できるのは良いニュースです。 これは、必要に応じてバージョン2に安全にリファクタリングできることを意味します。
コアドメインの設計
Section titled “コアドメインの設計”異なる型間で損失なく変換できることを知ると、必要に応じてドメイン設計を調整できます。
たとえば、この型:
type Something_V1 = | CaseA1 of TypeX * TypeY | CaseA2 of TypeX * TypeZは、次のように損失なく変換できます。
type Inner = | CaseA1 of TypeY | CaseA2 of TypeZ
type Something_V2 = TypeX * Innerあるいは、次のようにもできます。
type Something_V3 = { x: TypeX inner: Inner }実際の例を見てみましょう:
- 登録ユーザーと未登録ユーザーがいるウェブサイトがあります。
- すべてのユーザーにセッションIDがあります。
- 登録ユーザーにのみ、追加情報があります。
この要件を次のようにモデル化できます。
module Customer_V1 =
type UserInfo = {name:string} //など type SessionId = SessionId of int
type WebsiteUser = | RegisteredUser of SessionId * UserInfo | GuestUser of SessionIdあるいは、共通のSessionIdを上位レベルに引き上げて、次のようにもできます。
module Customer_V2 =
type UserInfo = {name:string} //など type SessionId = SessionId of int
type WebsiteUserInfo = | RegisteredUser of UserInfo | GuestUser
type WebsiteUser = { sessionId : SessionId info: WebsiteUserInfo }どちらが良いでしょうか?ある意味では、両方とも「同じ」ですが、使用パターンによって最適な設計は異なります。
- ユーザーの種類をセッションIDより重視する場合は、バージョン1が良いでしょう。
- ユーザーの種類を気にせず、常にセッションIDを見る場合は、バージョン2が良いでしょう。
これらが同型であることを知っていれば、必要に応じて両方の型を定義し、異なるコンテキストで使用し、必要に応じて損失なく相互に変換できるのが良い点です。
外部世界とのインターフェース
Section titled “外部世界とのインターフェース”DirectionやWebsiteUserのようなきれいなドメイン型がありますが、どこかで外部世界とインターフェースを取る必要があります。
データベースに保存したり、JSONとして受け取ったりする場合などです。
問題は、外部世界には素晴らしい型システムがないことです!すべてが文字列、整数、ブール値などのプリミティブになりがちです。
私たちのドメインから外部世界に行くことは、「小さな」値の集合から「大きな」値の集合への移行を意味し、これは簡単にできます。 しかし、外部世界から私たちのドメインに入ってくるということは、「大きな」値の集合から「小さな」値の集合への移行を意味し、これには検証とエラーケースが必要です。
たとえば、ドメイン型は次のようになるかもしれません:
type DomainCustomer = { Name: String50 Email: EmailAddress Age: PositiveIntegerLessThan130 }値には制約があります:名前は最大50文字、検証済みのメールアドレス、1から129の間の年齢です。
一方、DTO型は次のようになるかもしれません:
type CustomerDTO = { Name: string Email: string Age: int }値に制約はありません:名前は任意の文字列、未検証のメールアドレス、2^32の異なる値(負の値を含む)を取り得る年齢です。
これは、CustomerDTOからDomainCustomerへのマッピングを作成できないことを意味します。
無効な入力をマッピングするために、少なくとも1つの別の値(DomainCustomer + 1)が必要で、できれば様々なエラーを文書化するためにさらに多くの値が必要です。
これは自然に、私の関数型エラー処理の講演で説明したSuccess/Failureモデルにつながります。
最終的なマッピングは、CustomerDTOからSuccessFailure<DomainCustomer>または類似のものへのマッピングになります。
これから最後のルールが導かれます:
- ルール:誰も信用しないこと。外部ソースからデータをインポートする場合は、必ず無効な入力を処理すること。
このルールを真剣に受け止めると、いくつかの影響があります:
- ドメイン型に直接デシリアライズしようとしない(例:ORMは使用しない)。DTOタイプにのみデシリアライズする。
- データベースやその他の「信頼できる」ソースから読み取るすべてのレコードを常に検証する。
すべてがSuccess/Failure型でラップされていると面倒になると思うかもしれません。それは事実ですが(!)、これを簡単にする方法があります。
たとえば、この投稿を参照してください。
さらに読むべき資料
Section titled “さらに読むべき資料”代数的型の「代数」はよく知られています。最近の良いまとめとして、 “The algebra (and calculus!) of algebraic data types” とChris Taylorによるシリーズがあります。
この記事を書いた後、2つの類似した投稿を指摘されました:
- Tomas Petricekによるもので、ほぼ同じ内容です!
- Bartosz Milewskiによるもので、圏論のシリーズの一部です。
一部の記事で触れられていますが、代数的型の数式を使って、微分など、興味深い操作ができます!
学術論文が好きな方は、2001年のConor McBrideによる”The Derivative of a Regular Type is its Type of One-Hole Contexts” (PDF)で元の議論を読むことができ、 2005年のAbbott、Altenkirch、Ghani、McBrideによる”Differentiating Data Structures” (PDF)でフォローアップを読むことができます。
この記事は世界で最も刺激的なトピックではないかもしれませんが、私はこのアプローチを興味深く、また有用だと感じ、皆さんと共有したいと思いました。
あなたの考えを聞かせてください。読んでいただきありがとうございます!