依存関係の注入の6つのアプローチ
この記事は 2020年 F# アドベントカレンダー の一部です。 他の素晴らしい投稿もぜひご覧ください! また、このイベントを企画してくれた Sergey Tihon さんに特別な感謝を。
この投稿シリーズでは、「依存関係の注入(Dependency Injection)」を行う6つの異なるアプローチを見ていきます。
この記事は Mark Seemann による同様の投稿シリーズ に触発されたもので、同じアイデアを少し異なる形で紹介しています。このテーマに関しては、Bartosz Sypytkowski や Carsten König による優れた記事もありますので、そちらも読む価値があります!
これから紹介する6つのアプローチは以下の通りです:
- 依存関係の保持:依存関係の管理を気にせず、すべてをインラインでハードコードするアプローチです。
- 依存関係の排除:Mark Seemann が提唱した素晴らしい用語で、コアのビジネスロジックコードからあらゆる依存関係を排除する方法です。I/O や他の不純なコードをドメインの「端」にとどめます。
- 依存関係のパラメータ化:すべての依存関係を関数の引数として渡す方法です。部分適用と一緒に使われることがよくあります。
- 依存関係の注入とReader モナド:コードの構築後に依存関係を渡す方法です。オブジェクト指向スタイルではコンストラクタ注入として、関数型スタイルでは Reader モナドとして対応します。
- 依存関係の解釈:依存関係への呼び出しをデータ構造に置き換え、後で解釈する方法です。オブジェクト指向では インタープリターパターン、関数型では Free モナド などが該当します。
各アプローチについて、実装例を見てから、それぞれの利点と欠点を検討していきます。 また、シリーズの最後の投稿では、異なる例を取り上げて、再度6通りの実装を行います。
※なお、以前に 似たような記事 を書きましたが、今では本シリーズの内容がそれを置き換えるものとなっています。
「依存関係」とは何か?
Section titled “「依存関係」とは何か?”本題に入る前に、この記事における「依存関係(Dependency)」の定義を明確にしておきましょう。ここでは、「関数 A が関数 B を呼び出すとき、A は B に依存している」とします。つまり、これは呼び出し元と呼び出し先の関係であり、データ依存関係やライブラリ依存関係など、ソフトウェア開発で扱う他の種類の依存関係とは異なります。
このような依存関係は日常的に発生しますが、どのような依存関係が問題なのでしょうか?
まず、一般的には予測可能で決定的(純粋)なコードを作りたいと考えます。非決定的な呼び出し(I/O、乱数生成、現在時刻の取得など)はこの性質を壊してしまうため、そうした不純な依存関係は適切に管理・制御する必要があります。
次に、コードが純粋であっても、実装を変更可能にして動的な振る舞いを切り替えたい場面があります。オブジェクト指向ではストラテジーパターンを使うでしょうし、関数型では「ストラテジー関数」を引数として渡すことが多いです。
その他の依存関係については、特別な管理は不要です。もし純粋なクラス/モジュール/関数が一つだけ存在するなら、直接呼び出せば良いのです。モックを用意したり、不要な抽象化を加えたりする必要はありません。
まとめると、以下の2種類の依存関係が特別な配慮を要します:
- 非純粋な依存関係:非決定性をもたらし、テストを困難にします。
- 「ストラテジー」依存関係:複数の実装を使い分けることを可能にします。
ワークフロー指向の設計
Section titled “ワークフロー指向の設計”以下のコードではすべて「ワークフロー指向」の設計を採用しています。ここでいう「ワークフロー」とは、ビジネス取引、ストーリー、ユースケースなどを指します。 このアプローチの詳細については、私の講演「Reinventing The Transaction Script」をご覧ください。 (オブジェクト指向寄りの視点であれば、Jimmy Bogard による「Vertical Slice Architecture」も参考になります。)
非常にシンプルな要件を用意し、それを6通りの方法で実装してみましょう。
要件は次の通りです:
- 入力から2つの文字列を読み取る
- それらを比較する
- 1つ目の文字列が大きいか、小さいか、または等しいかを表示する
以上です。単純な内容ですが、どれだけ複雑にできるか見てみましょう!
アプローチ #1:依存関係の保持
Section titled “アプローチ #1:依存関係の保持”まずは、最もシンプルな実装から始めましょう。
let compareTwoStrings() = printfn "1つ目の値を入力してください" let str1 = Console.ReadLine() printfn "2つ目の値を入力してください" let str2 = Console.ReadLine()
if str1 > str2 then printfn "1つ目の値のほうが大きいです" else if str1 < str2 then printfn "1つ目の値のほうが小さいです" else printfn "値は等しいです"このように、要件をそのまま直接実装しており、抽象化や複雑化は一切ありません。
このアプローチの利点は、そのシンプルさにあります。実装が明快で理解しやすく、 特に小規模なプロジェクトでは、抽象化を加えることでかえって保守性が下がることもあります。
一方、欠点はテストが不可能であることです。関数のシグネチャは unit -> unit であり、有用な入力も出力も取り扱いません。テストするには、何度も実行して手作業で入力を変えるしかありません。
このアプローチが適しているのは以下のような場合です:
- テストや抽象化の価値がない、単純なスクリプト
- 要件を素早く理解するための使い捨てスケッチやプロトタイプ
- ビジネスロジックが最小限で、入力と出力の連携が主な役割であるプログラム 例:ETLパイプライン、データサイエンスのスクリプト(多くの場合、手動で結果を確認)
アプローチ #2:依存関係の排除
Section titled “アプローチ #2:依存関係の排除”コードを予測可能でテストしやすくする最も簡単な方法の一つは、不純な依存関係を排除し、純粋なコードだけを残すことです。これを「依存関係の排除」と呼びます。
たとえば、上記の最初の実装では、不純な I/O 呼び出し(printfn や ReadLine)が、純粋な比較処理(if str1 > str2)と混在していました。

もし、コードの中に純粋な処理だけを残したいのであれば、何を変える必要があるでしょうか?
- まず、コンソールから読み取ったすべての値は、関数の引数として渡される必要があります。
- 次に、判定結果は I/O を伴わない純粋なデータ構造として返される必要があります。
これらの変更を加えると、コードは次のようになります:
module PureCore =
type ComparisonResult = | Bigger | Smaller | Equal
let compareTwoStrings str1 str2 = if str1 > str2 then Bigger else if str1 < str2 then Smaller else Equalこの新しい実装では、I/O に関する処理は完全に排除されています。
このコードは完全に決定的であり、以下のようなテストスイート(Expecto テストライブラリ を使用)で簡単にテストできます。
testCase "smaller" <| fun () -> let expected = PureCore.Smaller let actual = PureCore.compareTwoStrings "a" "b" Expect.equal actual expected "a < b"
testCase "equal" <| fun () -> let expected = PureCore.Equal let actual = PureCore.compareTwoStrings "a" "a" Expect.equal actual expected "a = a"
testCase "bigger" <| fun () -> let expected = PureCore.Bigger let actual = PureCore.compareTwoStrings "b" "a" Expect.equal actual expected "b > a"しかし、この純粋なコードを実際に「使う」にはどうすればよいでしょうか?それには、呼び出し元が入力を提供し、出力に対して何らかの処理を行う必要があります。一般に、I/O はコールスタックの最上位で行うのが理想です。この「最上位の層」は、「API層」「シェル層」「合成ルート」あるいは単に「プログラム本体」など、さまざまな名称で呼ばれます。
呼び出し元のコードは、次のようになります:
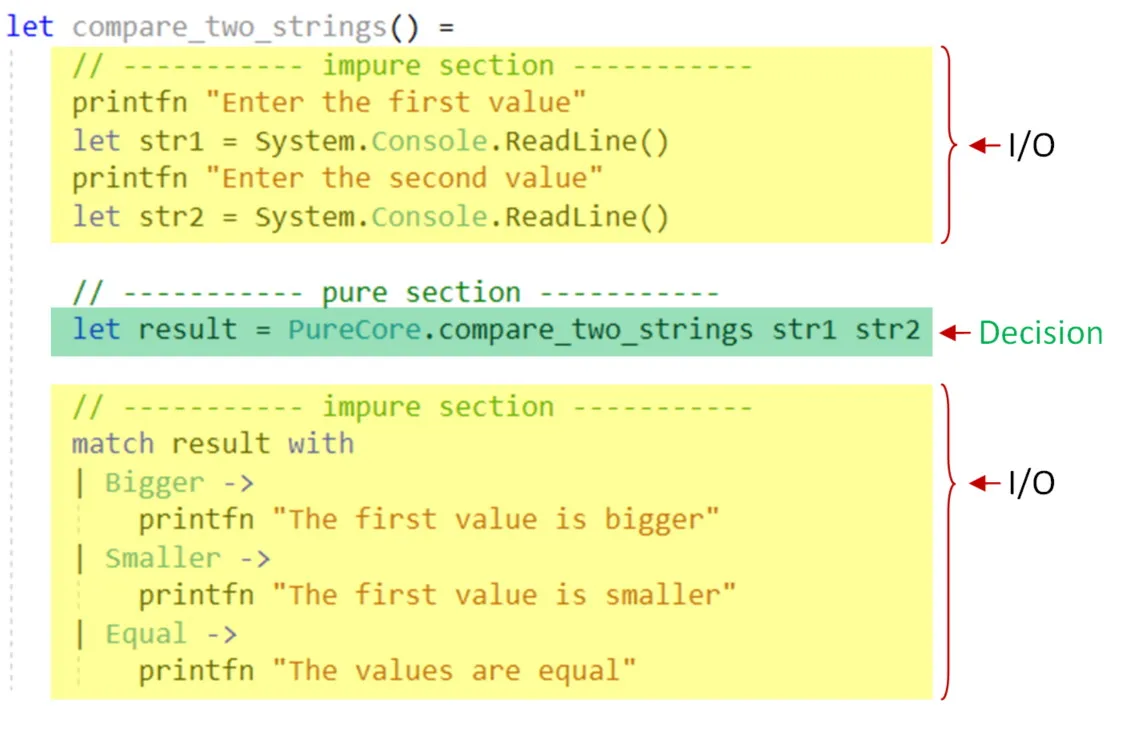
module Program = open PureCore
let program() = // ----------- 不純なセクション ----------- printfn "1つ目の値を入力してください" let str1 = Console.ReadLine() printfn "2つ目の値を入力してください" let str2 = Console.ReadLine()
// ----------- 純粋なセクション ----------- let result = PureCore.compareTwoStrings str1 str2
// ----------- 不純なセクション ----------- match result with | Bigger -> printfn "1つ目の値のほうが大きいです" | Smaller -> printfn "1つ目の値のほうが小さいです" | Equal -> printfn "値は等しいです"「依存関係の排除」アプローチを使うと、このように不純/純粋/不純というサンドイッチ構造になります:
理想的な関数型パイプラインは、このような構造です:
- コンソール/ファイル/データベースなどからの I/O(非決定的コード)
- 純粋なビジネスロジック(意思決定)
- 結果をファイルやデータベースなどに保存する I/O
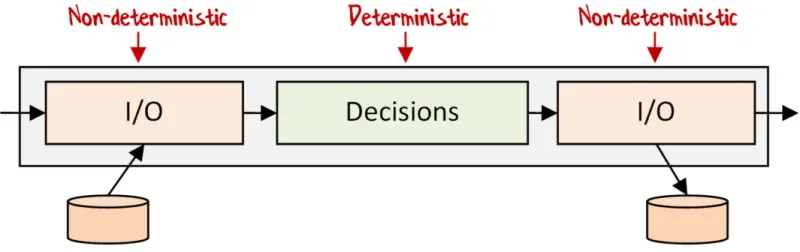
この構造の良い点は、I/O セグメントがそのワークフロー専用であるため、たとえば IRepository のような大規模な抽象インターフェースを作る必要がないことです。その結果、コードベース全体がシンプルになります。
多層サンドイッチ
Section titled “多層サンドイッチ”もし意思決定の途中で追加の I/O が必要になった場合はどうするでしょうか?その場合は、多層構造のサンドイッチにすることができます:

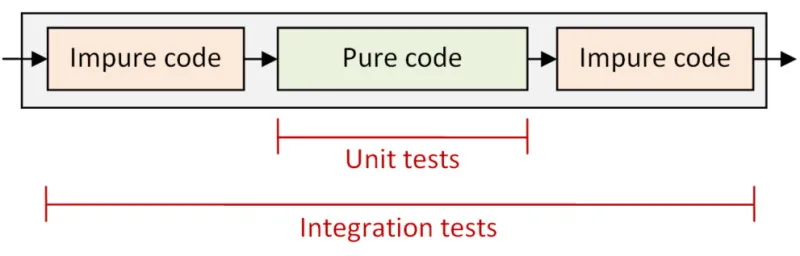
重要なのは、I/O セグメントと意思決定セグメントを明確に分離することです。これまで述べたような理由により、それが重要になります。
このアプローチのもう一つの利点は、テストの境界が明確になることです。中心の純粋なコードはユニットテストし、全体のパイプラインについては統合テストを行います。
本記事では、6つのアプローチのうち最初の2つ、「依存関係の保持」と「依存関係の排除」について見てきました。
「依存関係の排除」アプローチは、明確な利点があるため、可能な限り採用すべきです。唯一の欠点は、いくつかの間接化(indirection)が必要になることです:
- 純粋なコードが返す判定結果を表現するための、特別なデータ構造を定義する必要があります。
- 不純なコードを実行する上位レイヤーが必要となり、そのレイヤーが入力を純粋なコードに渡し、結果を解釈して再度 I/O に変換する必要があります。
この記事のソースコードは以下の Gist にあります:
次回の記事では、「依存関係のパラメータ化」について見ていきます。つまり、依存関係を通常の関数引数として渡す方法です。