実世界の循環依存とモジュール性
(2013-06-15更新。記事末尾のコメントを参照)
(2014-04-12更新。続編の記事でRoslynにも同様の分析を適用)
(2015-01-23更新。Evelina Gabasovaによるこの分析のより明確なバージョンを強くお勧めします。 彼女は本当にこの分野に詳しいので、まず彼女の記事を読むことをお勧めします!)
この記事は、モジュール構成と循環依存に関する以前の2つの記事の続編です。
C#とF#で書かれた実際のプロジェクトを比較し、モジュール性と循環依存の数がどのように異なるかを見てみるのは面白いと思いました。
C#で書かれたプロジェクトとF#で書かれたプロジェクトを10個ずつ程度選び、何らかの方法で比較する計画を立てました。
この作業に多くの時間をかけたくなかったので、ソースファイルを分析しようとするのではなく、少しずるをしてMono.Cecilライブラリを使用してコンパイルされたアセンブリを分析することにしました。
これにより、NuGetを使用して直接バイナリを入手することもできました。
選んだプロジェクトは以下の通りです。
C#プロジェクト
- Mono.Cecil、ECMA CIL形式のプログラムやライブラリを検査するもの。
- NUnit
- SignalR、リアルタイムWeb機能のため。
- NancyFx、Webフレームワーク。
- YamlDotNet、YAMLのパースと出力のため。
- SpecFlow、BDDツール。
- Json.NET。
- Entity Framework。
- ELMAH、ASP.NETのロギングフレームワーク。
- NuGet自体。
- Moq、モッキングフレームワーク。
- NDepend、コード分析ツール。
- 公平を期すため、私がC#で書いたビジネスアプリケーション。
F#プロジェクト
残念ながら、F#プロジェクトは選択の幅が広くありません。以下を選びました。
- FSharp.Core、F#のコアライブラリ。
- FSPowerPack。
- FsUnit、NUnitの拡張。
- Canopy、Seleniumテスト自動化ツールのラッパー。
- FsSql、優れたADO.NETラッパー。
- WebSharper、Webフレームワーク。
- TickSpec、BDDツール。
- FSharpx、F#ライブラリ。
- FParsec、パーサーライブラリ。
- FsYaml、FParsecを基にしたYAMLライブラリ。
- Storm、Webサービスのテストツール。
- Foq、モッキングフレームワーク。
- 今度はF#で書いた別のビジネスアプリケーション。
SpecFlowとTickSpec、MoqとFoqは直接比較可能なものとして選びました。
しかし、ご覧の通り、F#プロジェクトのほとんどはC#のものと直接比較できません。たとえば、NancyやEntity Frameworkに相当するF#プロジェクトはありません。
それでも、プロジェクトを比較することで何らかのパターンが観察できることを期待しました。そして、その期待は的中しました。結果については後ほど詳しく説明します!
どの指標を使うか
Section titled “どの指標を使うか”2つの点を調べたいと思いました。「モジュール性」と「循環依存」です。
まず、「モジュール性」の単位は何にすべきでしょうか。
コーディングの観点からは、通常ファイルを単位として作業します(Smalltalkは顕著な例外です)。そのため、ファイルをモジュール性の単位と考えるのが理にかなっています。ファイルは関連する項目をグループ化するために使用され、2つのコードが異なるファイルにある場合、同じファイル内にある場合ほど「関連性が強い」とは言えません。
C#では、ベストプラクティスとして1ファイルに1クラスを置きます。つまり、20ファイルは20クラスを意味します。クラスにはネストしたクラスがある場合もありますが、まれな例外を除いて、ネストしたクラスは親クラスと同じファイルにあります。これは、ネストしたクラスを無視し、トップレベルのクラスをファイルの代わりとしてモジュール性の単位として使用できることを意味します。
F#では、ベストプラクティスとして1ファイルに1つのモジュール(時にはそれ以上)を置きます。つまり、20ファイルは20モジュールを意味します。裏側では、モジュールは静的クラスに変換され、モジュール内で定義されたクラスはネストしたクラスに変換されます。したがって、ここでもネストしたクラスを無視し、トップレベルのクラスをモジュール性の単位として使用できます。
C#とF#のコンパイラは、LINQやラムダ式などのために多くの「隠れた」型を生成します。場合によっては、これらを除外し、明示的にコード化された「作成された」型のみを含めたいことがあります。 また、F#の判別共用体から生成されるケースクラスも「作成された」クラスとは見なしません。つまり、3つのケースを持つ共用体型は4つではなく1つの作成された型としてカウントされます。
したがって、トップレベル型の定義は次のようになります。ネストされておらず、コンパイラによって生成されていない型です。
モジュール性の指標として選んだのは以下の通りです。
- トップレベル型の数。上記の定義による。
- 作成された型の数。上記の定義による。
- すべての型の数。この数にはコンパイラが生成した型も含まれます。トップレベル型の数と比較することで、トップレベル型がどの程度代表的かがわかります。
- プロジェクトのサイズ。明らかに、大きなプロジェクトにはより多くの型があるので、プロジェクトのサイズに基づいて調整する必要があります。選んだサイズの指標は、ファイルの物理的なサイズではなく命令の数です。これにより、埋め込みリソースなどの問題を排除できます。
モジュール性の単位が決まったら、モジュール間の依存関係を見ることができます。
この分析では、同じアセンブリ内の型間の依存関係のみを含めたいと思います。つまり、StringやListなどのシステム型への依存は依存関係としてカウントしません。
トップレベル型Aと別のトップレベル型Bがあるとします。以下の場合、AからBへの依存関係が存在すると言えます。
- 型
Aまたはそのネストした型が、型Bまたはそのネストした型から継承(または実装)している。 - 型
Aまたはそのネストした型が、型Bまたはそのネストした型をパラメータまたは戻り値として参照するフィールド、プロパティ、メソッドを持っている。これにはプライベートメンバーも含まれます。結局のところ、依存関係には変わりありません。 - 型
Aまたはそのネストした型が、型Bまたはそのネストした型を参照するメソッド実装を持っている。
これは完璧な定義ではないかもしれません。しかし、私の目的には十分です。
すべての依存関係に加えて、「公開」または「公開された」依存関係を見るのも有用かもしれないと考えました。AからBへの公開依存関係は以下の場合に存在します。
- 型
Aまたはそのネストした型が、型Bまたはそのネストした型から継承(または実装)している。 - 型
Aまたはそのネストした型が、型Bまたはそのネストした型をパラメータまたは戻り値として参照する公開フィールド、プロパティ、メソッドを持っている。 - 最後に、公開依存関係は、ソース型自体が公開されている場合にのみカウントされます。
依存関係の指標として選んだのは以下の通りです。
- 依存関係の総数。これは単にすべての型のすべての依存関係の合計です。大きなプロジェクトにはより多くの依存関係があることは明らかですが、プロジェクトのサイズも考慮に入れます。
- X個以上の依存関係を持つ型の数。これにより、「過度に」複雑な型がいくつあるかがわかります。
この依存関係の定義に基づくと、循環依存は2つの異なるトップレベル型が互いに依存する場合に発生します。
この定義に含まれないものに注意してください。モジュール内のネストした型が同じモジュール内の別のネストした型に依存する場合、それは循環依存ではありません。
循環依存がある場合、すべてのモジュールがリンクされた集合があります。たとえば、AがBに依存し、BがCに依存し、CがAに依存する場合、A、B、Cはリンクされています。グラフ理論では、これを強連結成分と呼びます。
循環依存の指標として選んだのは以下の通りです。
- サイクルの数。つまり、1つ以上のモジュールを含む強連結成分の数です。
- 最大の成分のサイズ。これにより、依存関係がどの程度複雑かがわかります。
すべての依存関係と公開依存関係のみの両方について循環依存を分析しました。
まず、NuGetを使用して各プロジェクトのバイナリをダウンロードしました。次に、各アセンブリに対して以下の手順を実行する小さなF#スクリプトを作成しました。
- Mono.Cecilを使用してアセンブリを分析し、ネストした型を含むすべての型を抽出。
- 各型について、他の型への公開参照と実装参照を抽出し、内部(同じアセンブリ)と外部(異なるアセンブリ)に分類。
- 「トップレベル」型のリストを作成。
- 下位レベルの依存関係に基づいて、各トップレベル型から他のトップレベル型への依存関係リストを作成。
この依存関係リストを使用して、以下に示すさまざまな統計を抽出しました。また、依存関係グラフをSVG形式で描画しました(graphVizを使用)。
サイクル検出には、QuickGraphライブラリを使用して強連結成分を抽出し、さらに処理と描画を行いました。
詳細が気になる方は、使用したスクリプトへのリンクと生データを用意しました。
これは適切な統計的研究ではなく、単なる簡単な分析であることを認識することが重要です。しかし、結果は非常に興味深いものでした。以下でその詳細を見ていきましょう。
モジュール性
Section titled “モジュール性”まずモジュール性から見ていきましょう。
C#プロジェクトのモジュール性関連の結果は以下の通りです。
| プロジェクト | コードサイズ | トップレベル型 | 作成された型 | すべての型 | コード/トップ | コード/作成 | コード/すべて | 作成/トップ | すべて/トップ |
|---|---|---|---|---|---|---|---|---|---|
| ef | 269521 | 514 | 565 | 876 | 524 | 477 | 308 | 1.1 | 1.7 |
| jsonDotNet | 148829 | 215 | 232 | 283 | 692 | 642 | 526 | 1.1 | 1.3 |
| nancy | 143445 | 339 | 366 | 560 | 423 | 392 | 256 | 1.1 | 1.7 |
| cecil | 101121 | 240 | 245 | 247 | 421 | 413 | 409 | 1.0 | 1.0 |
| nuget | 114856 | 216 | 237 | 381 | 532 | 485 | 301 | 1.1 | 1.8 |
| signalR | 65513 | 192 | 229 | 311 | 341 | 286 | 211 | 1.2 | 1.6 |
| nunit | 45023 | 173 | 195 | 197 | 260 | 231 | 229 | 1.1 | 1.1 |
| specFlow | 46065 | 242 | 287 | 331 | 190 | 161 | 139 | 1.2 | 1.4 |
| elmah | 43855 | 116 | 140 | 141 | 378 | 313 | 311 | 1.2 | 1.2 |
| yamlDotNet | 23499 | 70 | 73 | 73 | 336 | 322 | 322 | 1.0 | 1.0 |
| fparsecCS | 57474 | 41 | 92 | 93 | 1402 | 625 | 618 | 2.2 | 2.3 |
| moq | 133189 | 397 | 420 | 533 | 335 | 317 | 250 | 1.1 | 1.3 |
| ndepend | 478508 | 734 | 828 | 843 | 652 | 578 | 568 | 1.1 | 1.1 |
| ndependPlat | 151625 | 185 | 205 | 205 | 820 | 740 | 740 | 1.1 | 1.1 |
| personalCS | 422147 | 195 | 278 | 346 | 2165 | 1519 | 1220 | 1.4 | 1.8 |
| 合計 | 2244670 | 3869 | 4392 | 5420 | 580 | 511 | 414 | 1.1 | 1.4 |
F#プロジェクトの結果は以下の通りです。
| プロジェクト | コードサイズ | トップレベル型 | 作成された型 | すべての型 | コード/トップ | コード/作成 | コード/すべて | 作成/トップ | すべて/トップ |
|---|---|---|---|---|---|---|---|---|---|
| fsxCore | 339596 | 173 | 328 | 2024 | 1963 | 1035 | 168 | 1.9 | 11.7 |
| fsCore | 226830 | 154 | 313 | 1186 | 1473 | 725 | 191 | 2.0 | 7.7 |
| fsPowerPack | 117581 | 93 | 150 | 410 | 1264 | 784 | 287 | 1.6 | 4.4 |
| storm | 73595 | 67 | 70 | 405 | 1098 | 1051 | 182 | 1.0 | 6.0 |
| fParsec | 67252 | 8 | 24 | 245 | 8407 | 2802 | 274 | 3.0 | 30.6 |
| websharper | 47391 | 52 | 128 | 285 | 911 | 370 | 166 | 2.5 | 5.5 |
| tickSpec | 30797 | 34 | 49 | 170 | 906 | 629 | 181 | 1.4 | 5.0 |
| websharperHtml | 14787 | 18 | 28 | 72 | 822 | 528 | 205 | 1.6 | 4.0 |
| canopy | 15105 | 6 | 16 | 103 | 2518 | 944 | 147 | 2.7 | 17.2 |
| fsYaml | 15191 | 7 | 11 | 160 | 2170 | 1381 | 95 | 1.6 | 22.9 |
| fsSql | 15434 | 13 | 18 | 162 | 1187 | 857 | 95 | 1.4 | 12.5 |
| fsUnit | 1848 | 2 | 3 | 7 | 924 | 616 | 264 | 1.5 | 3.5 |
| foq | 26957 | 35 | 48 | 103 | 770 | 562 | 262 | 1.4 | 2.9 |
| personalFS | 118893 | 30 | 146 | 655 | 3963 | 814 | 182 | 4.9 | 21.8 |
| 合計 | 1111257 | 692 | 1332 | 5987 | 1606 | 834 | 186 | 1.9 | 8.7 |
各列の説明。
- コードサイズはCecilが報告するすべてのメソッドのCIL命令の数です。
- トップレベル型は上記の定義を使用したアセンブリ内のトップレベル型の総数です。
- 作成された型は、ネストした型、列挙型などを含むアセンブリ内の型の総数ですが、コンパイラが生成した型は除外しています。
- すべての型は、コンパイラが生成した型を含むアセンブリ内の型の総数です。
これらの基本的な指標に、いくつかの追加の計算列を加えました。
- コード/トップはトップレベル型/モジュールあたりのCIL命令の数です。これは各モジュール性の単位に関連付けられたコードの量を示す指標です。一般的に、多いほど良いと言えます。複数のファイルを扱う必要がないからです。一方で、トレードオフもあります。1つのファイルに多すぎるコード行があると、コードの読解が困難になります。C#とF#の両方において、1ファイルあたり500〜1000行のコードが良い実践とされており、調査したソースコードでもいくつかの例外を除いてそうなっているようです。
- コード/作成は作成された型あたりのCIL命令の数です。これは各作成された型の「大きさ」を示す指標です。
- コード/すべては型あたりのCIL命令の数です。これは各型の「大きさ」を示す指標です。
- 作成/トップはトップレベル型に対する作成された型すべての比率です。これは各モジュール性の単位に含まれる作成された型の概算数を示します。
- すべて/トップはトップレベル型に対するすべての型の比率です。これは各モジュール性の単位に含まれる型の概算数を示します。
最初に気づいたのは、いくつかの例外を除いて、C#プロジェクトのコードサイズがF#プロジェクトよりも大きいことです。部分的には、より大きなプロジェクトを選んだからです。しかし、SpecFlowとTickSpecのような比較的似たプロジェクトでも、SpecFlowのコードサイズの方が大きいです。SpecFlowがTickSpecよりも多くの機能を持っている可能性もありますが、F#でより汎用的なコードを使用した結果かもしれません。現時点ではどちらとも言えません。本当に同等の比較を行うには、さらなる調査が必要でしょう。
次に、トップレベル型の数について見てみましょう。先ほど、これはプロジェクト内のファイル数に相当するはずだと述べました。本当にそうでしょうか?
すべてのプロジェクトのソースを入手して徹底的にチェックしたわけではありませんが、いくつかのサンプルチェックを行いました。たとえば、Nancyには339のトップレベルクラスがあり、約339のファイルがあるはずです。実際には322の.csファイルがあったので、悪くない推定と言えます。
一方、SpecFlowには242のトップレベル型がありますが、.csファイルは171個しかないので、ここではやや過大評価しています。Cecilでも同様で、240のトップレベルクラスがありますが、.csファイルは128個しかありません。
FSharpXプロジェクトでは、173のトップレベルクラスがあり、約173のファイルがあるはずです。実際には78の.fsファイルしかないので、2倍以上の過大評価となっています。Stormを見ても、67のトップレベルクラスがありますが、実際には35の.fsファイルしかないので、やはり2倍の過大評価となっています。
したがって、トップレベルクラスの数は常にファイル数を過大評価しているようですが、C#よりもF#の方がその傾向が強いようです。この分野についてはさらに詳細な分析が必要かもしれません。
コードサイズとトップレベル型の数の比率
Section titled “コードサイズとトップレベル型の数の比率”F#コードの「コード/トップ」比率は、C#コードよりも一貫して大きくなっています。全体として、C#の平均的なトップレベル型は580命令に変換されます。しかしF#ではその数は1606命令で、約3倍になっています。
これはF#コードがC#コードよりも簡潔であるためだと予想されます。1つのモジュールに500行のF#コードがあれば、500行のC#コードよりもはるかに多くのCIL命令が生成されるのではないでしょうか。
「コードサイズ」と「トップレベル型」を視覚的にプロットすると、以下のようなグラフになります。
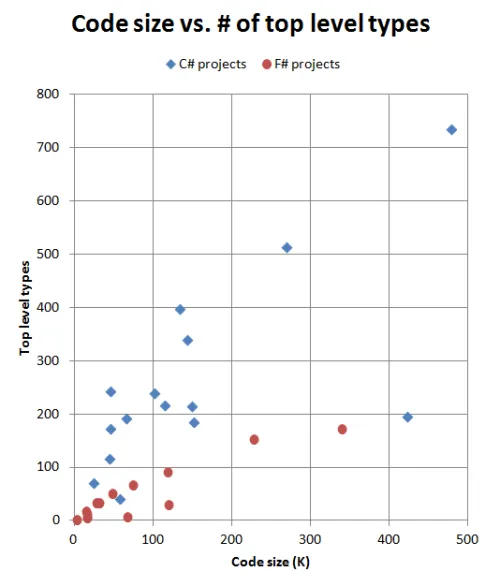
驚いたことに、このグラフではF#とC#のプロジェクトがはっきりと区別されています。C#プロジェクトは、プロジェクトサイズが異なっても、1000命令あたり1〜2のトップレベル型という一貫した比率を示しているようです。 F#プロジェクトも一貫しており、1000命令あたり約0.6のトップレベル型という比率を示しています。
実際、F#プロジェクトのトップレベル型の数は、プロジェクトが大きくなるにつれてC#プロジェクトのように線形に増加するのではなく、頭打ちになる傾向があるようです。
このグラフから読み取れるメッセージは、同じサイズのプロジェクトであれば、F#の実装の方がモジュールの数が少なく、結果として複雑さも低くなる可能性があるということです。
おそらく2つの例外に気づいたでしょう。2つのC#プロジェクトが外れ値になっています。50KマークにあるのはFParsecCSで、425Kマークにあるのは私のビジネスアプリケーションです。
FParsecCSについては、パーサーには必然的に大きなC#クラスが必要なのだろうと確信しています。しかし、私のビジネスアプリケーションの場合、長年にわたって蓄積された不要なコードが原因だと分かっています。 実際、巨大なクラスがいくつかあり、本来ならより小さなクラスに分割すべきものです。したがって、C#のコードベースではこのような指標は悪い兆候かもしれません。
コードサイズとすべての型の数の比率
Section titled “コードサイズとすべての型の数の比率”一方、コンパイラが生成したものを含むすべての型の数とコードの比率を比較すると、非常に異なる結果が得られます。
以下は「コードサイズ」と「すべての型」の対応するグラフです。
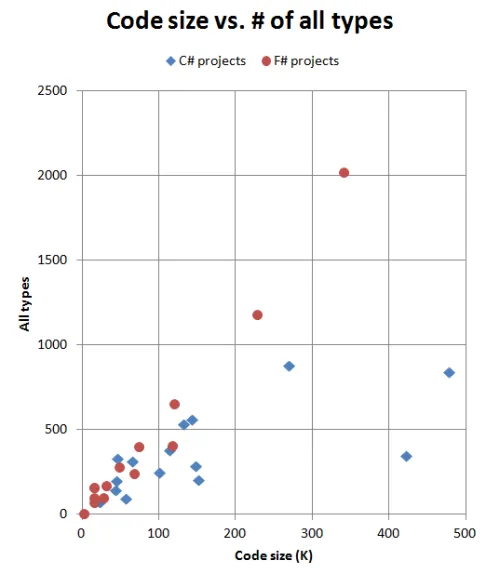
F#については驚くほど線形になっています。型の総数(コンパイラが生成したものを含む)は、プロジェクトのサイズと密接に関係しているようです。 一方、C#の型の数はかなりばらつきがあるようです。
型の平均「サイズ」は、C#コードよりもF#コードの方がやや小さくなっています。C#の平均的な型は約400命令に変換されます。しかしF#ではその数は約180命令です。
これが何故なのかはよく分かりません。F#の型がより細分化されているからでしょうか、それともF#コンパイラがC#コンパイラよりも多くの小さな型を生成しているからでしょうか?より詳細な分析を行わないと判断できません。
トップレベル型と作成された型の比率
Section titled “トップレベル型と作成された型の比率”コードサイズと型数を比較した後、今度は型数同士を比較してみましょう。
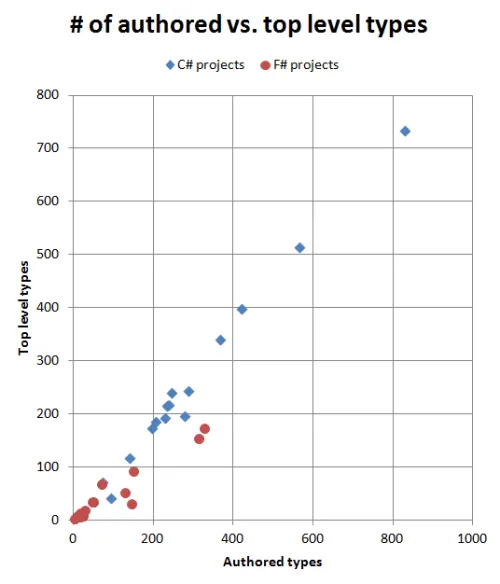
ここでも大きな違いが見られます。C#では、モジュール性の単位ごとに平均1.1の作成された型があります。しかしF#では平均1.9で、いくつかのプロジェクトではそれよりもはるかに多くなっています。
もちろん、F#ではネストした型の作成は簡単ですが、C#ではかなり珍しいので、これは公平な比較ではないと言えるかもしれません。 しかし、F#でたった数行で十数個の型を作成できる能力が、設計の質に何らかの影響を与えているのは確かでしょう。 C#でもこれは不可能ではありませんが、簡単ではありません。これは、C#では潜在的に可能な細かさを実現しようとする誘惑が少ないことを意味しているのではないでしょうか?
最も高い比率(4.9)を示しているのは、私のF#ビジネスアプリケーションです。これは、このリストの中で唯一、特定のビジネスドメインを中心に設計されたF#プロジェクトであるためだと考えています。 ここで説明されている概念を使用して、ドメインを正確にモデル化するために多くの「小さな」型を作成しました。DDDの原則を使用して作成された他のプロジェクトでも、 同じように高い数値が見られるはずです。
次に、トップレベルクラス間の依存関係を見てみましょう。
C#プロジェクトの結果は以下の通りです。
| プロジェクト | トップレベル型 | 依存関係の総数 | 依存/トップ | 1つ以上の依存 | 3つ以上の依存 | 5つ以上の依存 | 10以上の依存 | 図 |
|---|---|---|---|---|---|---|---|---|
| ef | 514 | 2354 | 4.6 | 76% | 51% | 32% | 13% | svg dotfile |
| jsonDotNet | 215 | 913 | 4.2 | 69% | 42% | 30% | 14% | svg dotfile |
| nancy | 339 | 1132 | 3.3 | 78% | 41% | 22% | 6% | svg dotfile |
| cecil | 240 | 1145 | 4.8 | 73% | 43% | 23% | 13% | svg dotfile |
| nuget | 216 | 833 | 3.9 | 71% | 43% | 26% | 12% | svg dotfile |
| signalR | 192 | 641 | 3.3 | 66% | 34% | 19% | 10% | svg dotfile |
| nunit | 173 | 499 | 2.9 | 75% | 39% | 13% | 4% | svg dotfile |
| specFlow | 242 | 578 | 2.4 | 64% | 25% | 17% | 5% | svg dotfile |
| elmah | 116 | 300 | 2.6 | 72% | 28% | 22% | 6% | svg dotfile |
| yamlDotNet | 70 | 228 | 3.3 | 83% | 30% | 11% | 4% | svg dotfile |
| fparsecCS | 41 | 64 | 1.6 | 59% | 29% | 5% | 0% | svg dotfile |
| moq | 397 | 1100 | 2.8 | 63% | 29% | 17% | 7% | svg dotfile |
| ndepend | 734 | 2426 | 3.3 | 67% | 37% | 25% | 10% | svg dotfile |
| ndependPlat | 185 | 404 | 2.2 | 67% | 24% | 11% | 4% | svg dotfile |
| personalCS | 195 | 532 | 2.7 | 69% | 29% | 19% | 7% | |
| 合計 | 3869 | 13149 | 3.4 | 70% | 37% | 22% | 9% |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
F#プロジェクトの結果は以下の通りです。
| プロジェクト | トップレベル型 | 依存関係の総数 | 依存/トップ | 1つ以上の依存 | 3つ以上の依存 | 5つ以上の依存 | 10以上の依存 | 図 |
|---|---|---|---|---|---|---|---|---|
| fsxCore | 173 | 76 | 0.4 | 30% | 4% | 1% | 0% | svg dotfile |
| fsCore | 154 | 287 | 1.9 | 55% | 26% | 14% | 3% | svg dotfile |
| fsPowerPack | 93 | 68 | 0.7 | 38% | 13% | 2% | 0% | svg dotfile |
| storm | 67 | 195 | 2.9 | 72% | 40% | 18% | 4% | svg dotfile |
| fParsec | 8 | 9 | 1.1 | 63% | 25% | 0% | 0% | svg dotfile |
| websharper | 52 | 18 | 0.3 | 31% | 0% | 0% | 0% | svg dotfile |
| tickSpec | 34 | 48 | 1.4 | 50% | 15% | 9% | 3% | svg dotfile |
| websharperHtml | 18 | 37 | 2.1 | 78% | 39% | 6% | 0% | svg dotfile |
| canopy | 6 | 8 | 1.3 | 50% | 33% | 0% | 0% | svg dotfile |
| fsYaml | 7 | 10 | 1.4 | 71% | 14% | 0% | 0% | svg dotfile |
| fsSql | 13 | 14 | 1.1 | 54% | 8% | 8% | 0% | svg dotfile |
| fsUnit | 2 | 0 | 0.0 | 0% | 0% | 0% | 0% | svg dotfile |
| foq | 35 | 66 | 1.9 | 66% | 29% | 11% | 0% | svg dotfile |
| personalFS | 30 | 111 | 3.7 | 93% | 60% | 27% | 7% | |
| 合計 | 692 | 947 | 1.4 | 49% | 19% | 8% | 1% |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
各列の説明。
- トップレベル型は、前述の通りアセンブリ内のトップレベル型の総数です。
- 依存関係の総数はトップレベル型間の依存関係の総数です。
- 依存/トップはトップレベル型/モジュールあたりの依存関係の数です。これは平均的なトップレベル型/モジュールが持つ依存関係の数を示す指標です。
- 1つ以上の依存は、1つ以上の他のトップレベル型に依存するトップレベル型の数です。
- 3つ以上の依存。上記と同様ですが、3つ以上の他のトップレベル型に依存する場合です。
- 5つ以上の依存。上記と同様です。
- 10以上の依存。上記と同様です。この数の依存関係を持つトップレベル型は、理解や保守が難しくなります。これはプロジェクトの複雑さを示す指標です。
図列には、依存関係から生成されたSVGファイルへのリンクと、SVGの生成に使用されたDOTファイルへのリンクが含まれています。 これらの図については後ほど説明します。 (私のアプリケーションの内部を公開することはできないので、指標のみを提示します)
これらの結果は非常に興味深いものです。C#では、プロジェクトサイズが大きくなるにつれて依存関係の総数が増加します。平均して、各トップレベル型は他の3〜4の型に依存しています。
一方、F#プロジェクトの依存関係の総数は、プロジェクトサイズにあまり左右されないようです。各F#モジュールは平均して1〜2の他のモジュールにしか依存していません。 最大のプロジェクト(FSharpX)は、多くの小さなプロジェクトよりも低い比率を示しています。私のビジネスアプリケーションとStormプロジェクトだけが例外です。
以下は、コードサイズと依存関係の数の関係を示すグラフです。
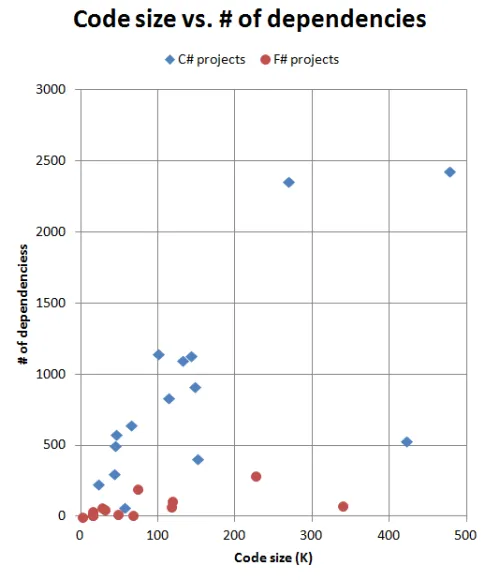
C#プロジェクトとF#プロジェクトの違いが非常に明確です。C#の依存関係はプロジェクトサイズに比例して線形に増加しているようです。一方、F#の依存関係は平坦なようです。
依存関係の分布
Section titled “依存関係の分布”トップレベル型あたりの平均依存関係数は興味深いですが、ばらつきを理解するには十分ではありません。多くの依存関係を持つモジュールがたくさんあるのでしょうか?それとも、各モジュールは少数の依存関係しか持たないのでしょうか?
これは保守性に影響を与える可能性があります。おそらく、1つか2つの依存関係しか持たないモジュールの方が、10個以上の依存関係を持つモジュールよりも、アプリケーションの文脈で理解しやすいでしょう。
洗練された統計分析を行う代わりに、シンプルに保ち、1つ以上の依存関係を持つトップレベル型の数、3つ以上の依存関係を持つトップレベル型の数、などを単純にカウントすることにしました。
以下は、同じ結果を視覚的に表示したものです。
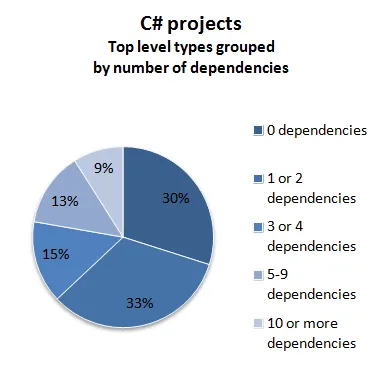
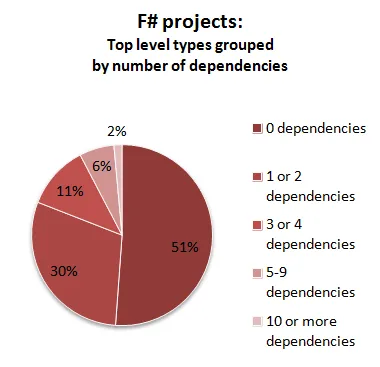
これらの数字から何が推測できるでしょうか?
-
まず、F#プロジェクトでは、モジュールの半分以上が外部依存関係を全く持っていません。これは少し驚きですが、C#プロジェクトと比べてジェネリクスを多用しているためだと考えられます。
-
次に、F#プロジェクトのモジュールは、C#プロジェクトのクラスと比べて一貫して依存関係が少ないです。
-
最後に、F#プロジェクトでは、多数の依存関係を持つモジュールはかなりまれで、全体の2%未満です。一方、C#プロジェクトでは、9%のクラスが10個以上の他のクラスへの依存関係を持っています。
F#グループで最も悪い例は、私自身のF#アプリケーションで、これらの指標に関しては私のC#アプリケーションよりも悪い結果となっています。 これは、ドメイン固有の型の形で非ジェネリックを多用しているためかもしれませんし、単にコードがさらなるリファクタリングを必要としているだけかもしれません!
依存関係の図
Section titled “依存関係の図”ここで依存関係の図を見てみるのも有用かもしれません。これらはSVGファイルなので、ブラウザで表示できるはずです。
ほとんどの図が非常に大きいことに注意してください。開いた後、全体を見るためには大きくズームアウトする必要があります!
まずはSpecFlowとTickSpecの図を比較してみましょう。
SpecFlowの図はこちらです。

TickSpecの図はこちらです。

各図は、プロジェクト内で見つかったすべてのトップレベル型をリストアップしています。ある型から別の型への依存関係がある場合、矢印で示されています。 可能な限り依存関係は左から右に向かって示されているので、右から左に向かう矢印は循環依存があることを意味します。
レイアウトはグラフビズによって自動的に行われていますが、一般的に型は列または「ランク」に整理されています。たとえば、SpecFlowの図には12のランクがあり、TickSpecの図には5つのランクがあります。
ご覧の通り、典型的な依存関係の図には通常、多くの入り組んだ線があります!図の複雑さは、コードの複雑さを視覚的に表現しているようなものです。 たとえば、SpecFlowプロジェクトの保守を任された場合、クラス間のすべての関係を理解するまでは本当に安心できないでしょう。そしてプロジェクトが複雑なほど、理解するのに時間がかかります。
オブジェクト指向設計 vs 関数型設計の違いが明らかに?
Section titled “オブジェクト指向設計 vs 関数型設計の違いが明らかに?”TickSpecの図はSpecFlowのものよりもはるかに単純です。これはTickSpecがSpecFlowほど多くの機能を持っていないからでしょうか?
答えは違います。機能の数とは全く関係がないと思います。むしろコードの組織化方法が異なるからです。
SpecFlowのクラス(dotfile)を見ると、インターフェースを作成することで優れたオブジェクト指向設計とTDDの実践に従っていることがわかります。
たとえば、TestRunnerManagerとITestRunnerManagerがあります。
また、オブジェクト指向設計でよく見られる他のパターンもたくさんあります。「リスナー」クラスとインターフェース、「プロバイダー」クラスとインターフェース、「コンパレーター」クラスとインターフェースなどです。
一方、TickSpecのモジュール(dotfile)を見ると、インターフェースは全くありません。また、「リスナー」や「プロバイダー」、「コンパレーター」もありません。 コード内でそのようなものが必要な場合もあるかもしれませんが、モジュールの外部には公開されていないか、より可能性が高いのは、その役割が型ではなく関数によって果たされているのでしょう。
ちなみに、SpecFlowのコードを批判しているわけではありません。よく設計されているように見えますし、非常に有用なライブラリです。ただ、オブジェクト指向設計と関数型設計の違いをいくつか浮き彫りにしていると思います。
MoqとFoqの比較
Section titled “MoqとFoqの比較”MoqとFoqの図も比較してみましょう。これら2つのプロジェクトはほぼ同じことを行っているので、コードは比較可能なはずです。
{kind=link}
{kind=link}
前と同様に、F#で書かれたプロジェクトの方が依存関係の図がはるかに小さくなっています。
Moqのクラス(dotfile)を見ると、分析から除外しなかった「Castle」ライブラリが含まれていることがわかります。 依存関係を持つ249のクラスのうち、Moq固有のものは66だけです。Moq名前空間内のクラスのみを考慮していれば、もっときれいな図が得られたかもしれません。
一方、Foqのモジュール(dotfile)を見ると、依存関係を持つモジュールは23しかなく、Moqのクラスだけでもそれより少ないです。
つまり、F#のコード組織化には何か大きな違いがあるのです。
FParsecとFParsecCSの比較
Section titled “FParsecとFParsecCSの比較”FParsecプロジェクトは興味深い自然実験です。このプロジェクトには2つのアセンブリがあり、サイズはほぼ同じですが、1つはC#で書かれ、もう1つはF#で書かれています。
C#コードは高速な解析のために設計されており、F#コードはよりハイレベルなので、直接比較するのは少し不公平かもしれません。しかし…不公平を承知で比較してみましょう!
F#アセンブリの”FParsec”とC#アセンブリの”FParsecCS”の図がこちらです。
{kind=link}
{kind=link}
どちらもきれいで明確です。素晴らしいコードですね!
図からは明確ではありませんが、私の分析方法がC#アセンブリに不利に働いています。
たとえば、C#の図を見ると、Operator、OperatorType、InfixOperatorなどの間に依存関係があることがわかります。
しかし実際には、ソースコードを見るとこれらのクラスはすべて同じ物理ファイルにあります。
F#では、これらはすべて同じモジュールにあり、その関係は公開依存関係としてカウントされません。つまり、C#コードは不利な扱いを受けているのです。
それでも、ソースコードを見ると、C#コードは20のソースファイルがあるのに対し、F#は8つしかないので、複雑さに違いがあることは確かです。
何を依存関係とみなすか?
Section titled “何を依存関係とみなすか?”ただし、私の方法を擁護すると、これらのFParsec C#クラスを同じファイルにまとめているのは優れたコーディング実践だけであり、C#コンパイラによって強制されているわけではありません。 別の保守担当者が来て、知らずに異なるファイルに分離してしまうかもしれません。そうすると本当に複雑さが増してしまいます。F#ではそれほど簡単にはできませんし、少なくとも偶然にはできません。
つまり、「モジュール」と「依存関係」の定義によります。私の見方では、モジュールには本当に「密接に結びついた」もので、簡単に切り離すべきではないものが含まれます。 したがって、モジュール内の依存関係はカウントせず、モジュール間の依存関係はカウントします。
別の見方をすれば、F#は一部の領域(モジュール)で高い結合を奨励する代わりに、他の領域では低い結合を実現しています。C#では、利用可能な厳密な結合の唯一の種類はクラスベースです。 名前空間の使用など、それよりも緩い結合は、優れた実践やNDependのようなツールを使用して強制する必要があります。
F#のアプローチが良いか悪いかは好みの問題です。結果として、特定の種類のリファクタリングが難しくなる可能性があります。
最後に、あの忌まわしい循環依存に目を向けましょう。(なぜそれらが悪いのかについては、この記事を読んでください)
C#プロジェクトの循環依存の結果は以下の通りです。
| プロジェクト | トップレベル型 | サイクル数 | 参加 | 参加% | 最大成分サイズ | サイクル数(公開) | 参加(公開) | 参加%(公開) | 最大成分サイズ(公開) | 図 |
|---|---|---|---|---|---|---|---|---|---|---|
| ef | 514 | 14 | 123 | 24% | 79 | 1 | 7 | 1% | 7 | svg dotfile |
| jsonDotNet | 215 | 3 | 88 | 41% | 83 | 1 | 11 | 5% | 11 | svg dotfile |
| nancy | 339 | 6 | 35 | 10% | 21 | 2 | 4 | 1% | 2 | svg dotfile |
| cecil | 240 | 2 | 125 | 52% | 123 | 1 | 50 | 21% | 50 | svg dotfile |
| nuget | 216 | 4 | 24 | 11% | 10 | 0 | 0 | 0% | 1 | svg dotfile |
| signalR | 192 | 3 | 14 | 7% | 7 | 1 | 5 | 3% | 5 | svg dotfile |
| nunit | 173 | 2 | 80 | 46% | 78 | 1 | 48 | 28% | 48 | svg dotfile |
| specFlow | 242 | 5 | 11 | 5% | 3 | 1 | 2 | 1% | 2 | svg dotfile |
| elmah | 116 | 2 | 9 | 8% | 5 | 1 | 2 | 2% | 2 | svg dotfile |
| yamlDotNet | 70 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | svg dotfile |
| fparsecCS | 41 | 3 | 6 | 15% | 2 | 1 | 2 | 5% | 2 | svg dotfile |
| moq | 397 | 9 | 50 | 13% | 15 | 0 | 0 | 0% | 1 | svg dotfile |
| ndepend | 734 | 12 | 79 | 11% | 22 | 8 | 36 | 5% | 7 | svg dotfile |
| ndependPlat | 185 | 2 | 5 | 3% | 3 | 0 | 0 | 0% | 1 | svg dotfile |
| personalCS | 195 | 11 | 34 | 17% | 8 | 5 | 19 | 10% | 7 | svg dotfile |
| 合計 | 3869 | 683 | 18% | 186 | 5% | svg dotfile |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
F#プロジェクトの結果は以下の通りです。
| プロジェクト | トップレベル型 | サイクル数 | 参加 | 参加% | 最大成分サイズ | サイクル数(公開) | 参加(公開) | 参加%(公開) | 最大成分サイズ(公開) | 図 |
|---|---|---|---|---|---|---|---|---|---|---|
| fsxCore | 173 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | . |
| fsCore | 154 | 2 | 5 | 3% | 3 | 0 | 0 | 0% | 1 | svg dotfile |
| fsPowerPack | 93 | 1 | 2 | 2% | 2 | 0 | 0 | 0% | 1 | svg dotfile |
| storm | 67 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | . |
| fParsec | 8 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | . |
| websharper | 52 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 0 | . |
| tickSpec | 34 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | . |
| websharperHtml | 18 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | . |
| canopy | 6 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | . |
| fsYaml | 7 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | . |
| fsSql | 13 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | . |
| fsUnit | 2 | 0 | 0 | 0% | 0 | 0 | 0 | 0% | 0 | . |
| foq | 35 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | . |
| personalFS | 30 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | . |
| 合計 | 692 | 7 | 1% | 0 | 0% | . |
{kind=link}
{kind=link}
各列の説明。
- トップレベル型は、前述の通りアセンブリ内のトップレベル型の総数です。
- サイクル数は全体のサイクルの数です。理想的にはゼロになるはずです。しかし、数が多いからといって必ずしも悪いわけではありません。1つの巨大なサイクルよりも10個の小さなサイクルの方が良いと私は考えます。
- 参加。サイクルに参加しているトップレベル型の数です。
- 参加%。サイクルに参加しているトップレベル型の数を、全型に対する割合で表したものです。
- 最大成分サイズは最大の循環成分内のトップレベル型の数です。これはサイクルの複雑さを示す指標です。互いに依存する型が2つだけなら、123の型が互いに依存する場合に比べてサイクルははるかに単純です。
- **…(公開)**列は同じ定義ですが、公開依存関係のみを使用しています。公開依存関係のみに分析を限定するとどのような効果があるか見てみるのも興味深いと思いました。
- 図列にはサイクルの依存関係のみから生成されたSVGファイルへのリンクと、SVGの生成に使用されたDOTファイルへのリンクが含まれています。以下で分析します。
F#コードでサイクルを探そうとしても、がっかりするでしょう。F#プロジェクトでサイクルがあるのは2つだけで、それも非常に小さなものです。たとえば、FSharp.Coreでは、同じファイル内の隣接する2つの型の間に相互依存がありますが、これはここで見ることができます。
一方、ほぼすべてのC#プロジェクトに1つ以上のサイクルがあります。Entity Frameworkが最も多くのサイクルを持ち、クラスの24%が関与しています。Cecilが最悪の参加率で、 クラスの半分以上がサイクルに関与しています。
NDependでさえサイクルがありますが、公平を期すために言えば、これには正当な理由があるかもしれません。まず、NDependはクラス間ではなく名前空間間のサイクル除去に重点を置いています。また、 サイクルが同じソースファイルで宣言された型の間にある可能性があります。その結果、私の方法では良く組織化されたC#コードに対してやや不利に働く可能性があります(上記のFParsec vs FParsecCSの議論で述べたように)。
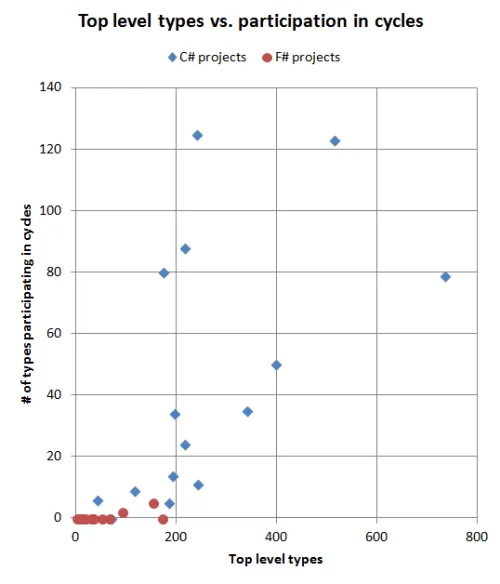
なぜC#とF#でこのような違いがあるのでしょうか?
- C#では、サイクルの作成を妨げるものは何もありません - これは偶発的な複雑さの完璧な例です。実際、それらを避けるには特別な努力が必要です。
- F#では、もちろん逆です。サイクルを簡単に作ることはできません。
私のビジネスアプリケーションの比較
Section titled “私のビジネスアプリケーションの比較”もう1つの比較をしてみましょう。私の日常業務の一部として、C#で多数のビジネスアプリケーションを書き、最近ではF#でも書いています。 ここにリストされている他のプロジェクトとは異なり、これらは特定のビジネスニーズに焦点を当てたもので、ドメイン固有のコード、カスタムビジネスルール、特別なケースなどがたくさんあります。
両プロジェクトは締め切りのプレッシャーの下で作られ、要件の変更や理想的なコードを書くことを妨げる通常の現実世界の制約のもとで作られました。私の立場にいる多くの開発者と同様に、 整理してリファクタリングする機会があればいいのですが、ビジネスは満足していて、新しいことに取り組まなければならないのです。
ともかく、これらを比較してみましょう。コードの詳細は指標以外は明かせませんが、それでも十分有用だと思います。
まずC#プロジェクトから見てみましょう。
- トップレベル型が195個あり、コード約2Kにつき1つです。他のC#プロジェクトと比較すると、これよりもはるかに多くのトップレベル型があるはずです。そして実際、そうだと分かっています。 多くのプロジェクト(このプロジェクトは6年前のものです)と同様に、特に締め切りが迫っている中では、リファクタリングよりも既存のクラスにメソッドを追加する方がリスクが低いのです。 古いコードを安定させることは、美しくすることよりも常に優先順位が高いのです!結果として、時間とともにクラスが大きくなりすぎてしまいます。
- クラスが大きいことの裏返しとして、クラス間の依存関係は少なくなっています!C#プロジェクトの中でも比較的良いスコアを示しています。 これは、依存関係だけが指標ではないことを示しています。バランスが必要です。
- 循環依存に関しては、C#プロジェクトとしては典型的です。いくつか(11個)ありますが、最大のものでも8つのクラスしか含んでいません。
次に、私のF#プロジェクトを見てみましょう。
- 30のモジュールがあり、コード約4Kにつき1つです。他のF#プロジェクトと比較すると、過剰ではありませんが、リファクタリングの余地はあるかもしれません。
- 余談ですが、このコードを保守した経験から、C#コードとは異なり、機能要求が来たときに既存のモジュールに無理にコードを追加する必要を感じないことに気づきました。 むしろ、多くの場合、新しい機能のためのコードをすべて新しいモジュールに入れる方が速くリスクが低いことがわかりました。 モジュールには状態がないため、関数はどこにでも存在できます - 同じクラスに存在する必要はありません。 時間が経つとこのアプローチも問題を引き起こす可能性がありますが(COBOLを思い出す人もいるかもしれません)、今のところ、新鮮な空気のように感じています。
- 指標を見ると、モジュールあたりの「作成された」型の数が異常に多いことがわかります(4.9)。前述のように、これはDDDスタイルの細かい設計の結果だと思います。 作成された型あたりのコード量は他のF#プロジェクトと同程度なので、サイズが大きすぎたり小さすぎたりすることはないようです。
- また、前に述べたように、モジュール間の依存関係はF#プロジェクトの中で最悪です。他のほぼすべてのモジュールに依存するいくつかのAPI/サービス関数があることは知っていますが、これは
リファクタリングが必要かもしれないという手がかりかもしれません。
- しかし、C#コードとは異なり、これらの問題のあるモジュールがどこにあるかを正確に知っています。これらのモジュールがすべてアプリケーションの最上位層にあり、Visual Studioのモジュールリストの一番下に表示されることをほぼ確信できます。 どうしてそんなに確信できるのでしょうか?なぜなら…
- 循環依存に関しては、F#プロジェクトとしては典型的です。つまり、まったくありません。
この分析は好奇心から始まりました - C#とF#プロジェクトの組織に意味のある違いはあるのでしょうか?
結果がこれほど明確だったことに驚きました。これらの指標を見れば、どの言語でアセンブリが書かれたかを確実に予測できるでしょう。
- プロジェクトの複雑さ。同じ命令数に対して、C#プロジェクトはF#プロジェクトよりもはるかに多くのトップレベル型(したがってファイル)を持つ傾向があります - 2倍以上のようです。
- 細かい粒度の型。同じ数のモジュールに対して、C#プロジェクトはF#プロジェクトよりも作成された型が少ない傾向があり、型の粒度がF#ほど細かくない可能性があります。
- 依存関係。C#プロジェクトでは、クラス間の依存関係の数がプロジェクトのサイズに比例して線形に増加します。F#プロジェクトでは、依存関係の数ははるかに少なく、比較的一定です。
- サイクル。C#プロジェクトでは、注意を払わないとサイクルが簡単に発生します。F#プロジェクトでは、サイクルは非常にまれで、存在しても非常に小さいです。
おそらく、これは言語の違いというよりも、プログラマーの能力の違いによるものではないでしょうか? まず、全体的にC#プロジェクトの品質はかなり良いと思います - 私がより良いコードを書けるとは決して言えません! そして、特に2つのケースでは、C#とF#のプロジェクトは同じ人物によって書かれたものですが、それでも違いが見られたので、このような議論は当てはまらないと思います。
単にバイナリを使用するこのアプローチは、限界に達しているかもしれません。より正確な分析を行うには、ソースコードからの指標も使用する必要があるでしょう(あるいはpdbファイルかもしれません)。
たとえば、「型あたりの命令数」が高いという指標は、ソースファイルが小さい(簡潔なコード)場合は良いことですが、大きい(膨れ上がったクラス)場合は良くありません。同様に、私のモジュール性の定義では、 ソースファイルではなくトップレベル型を使用したため、F#よりもC#にやや不利に働きました。
したがって、この分析が完璧だとは主張しません(そして分析コードにひどいミスをしていないことを願っています!)が、さらなる調査の有用な出発点になると思います。
2013-06-15更新
Section titled “2013-06-15更新”この投稿はかなりの関心を集めました。フィードバックに基づいて、以下の変更を加えました。
プロファイルされたアセンブリ
- FoqとMoqを追加しました(Phil Trelfordのリクエストにより)。
- FParsecのC#コンポーネントを追加しました(Dave Thomasほかのリクエストにより)。
- 2つのNDependアセンブリを追加しました。
- 私自身のプロジェクト2つ(C#とF#)を追加しました。
ご覧の通り、7つの新しいデータポイント(C#プロジェクト5つとF#プロジェクト2つ)を追加しても、全体的な分析結果は変わりませんでした。
アルゴリズムの変更
- 「作成された」型の定義をより厳密にしました。「GeneratedCodeAttribute」を持つ型とF#の合計型のサブタイプを除外しました。これはF#プロジェクトに影響を与え、「作成/トップ」比率をやや減少させました。
テキストの変更
- 分析の一部を書き直しました。
- YamlDotNetとFParsecの不公平な比較を削除しました。
- FParsecのC#コンポーネントとF#コンポーネントの比較を追加しました。
- MoqとFoqの比較を追加しました。
- 私自身の2つのプロジェクトの比較を追加しました。
オリジナルの投稿はこちらでまだ見ることができます。