6つのアプローチの再考
このシリーズでは、依存関係の注入に対する6つの異なるアプローチを見てきました。
- 最初の投稿では、「依存関係の保持」(コード内に直接埋め込む)と「依存関係の排除」(I/Oを実装の端に押し出す)について解説しました。
- 2番目の投稿では、通常の関数引数を用いて依存関係を注入する方法を見てきました。
- 3番目の投稿では、古典的なオブジェクト指向スタイルの依存関係の注入と、それに対応する関数型の手法である Reader モナドを紹介しました。
- 4番目の投稿では、インタープリターパターンを用いることで、依存関係そのものを回避する方法を見てきました。
この最後の投稿では、これら6つすべてのアプローチを使っていくつかの簡単な要件を実装し、その違いを確認できるようにします。何が起こっているのか詳細には説明しません。そのためには、以前の投稿を先に読んでいただくことをおすすめします。
具体的なユースケースを見て、それを基に異なる実装を試してみましょう。
ユーザーを持つ何らかのWebアプリがあり、各ユーザーは名前、メールアドレス、設定などを含む「プロファイル」を持っているとします。 プロファイルを更新するユースケースは、次のようになるかもしれません:
- 新しいプロファイルを受け取る(例えば、JSONリクエストから解析されたもの)
- ユーザーの現在のプロファイルをデータベースから読み取る
- プロファイルが変更された場合は、データベース内のユーザーのプロファイルを更新する
- メールアドレスが変更された場合は、ユーザーの新しいメールアドレスに確認メールメッセージを送信する
また、ログも少し追加します。
まず、使用するドメイン型から始めましょう:
module Domain = type UserId = UserId of int type UserName = string type EmailAddress = EmailAddress of string
type Profile = { UserId : UserId Name : UserName EmailAddress : EmailAddress }
type EmailMessage = { To : EmailAddress Body : string }そして、ロギング、データベース、メールのためのインフラストラクチャサービスは次のとおりです:
module Infrastructure = open Domain
type ILogger = abstract Info : string -> unit abstract Error : string -> unit
type InfrastructureError = | DbError of string | SmtpError of string
type DbConnection = DbConnection of unit // dummy definition
type IDbService = abstract NewDbConnection : unit -> DbConnection abstract QueryProfile : DbConnection -> UserId -> Async<Result<Profile,InfrastructureError>> abstract UpdateProfile : DbConnection -> Profile -> Async<Result<unit,InfrastructureError>>
type SmtpCredentials = SmtpCredentials of unit // dummy definition
type IEmailService = abstract SendChangeNotification : SmtpCredentials -> EmailMessage -> Async<Result<unit,InfrastructureError>>インフラストラクチャについて注意すべき点がいくつかあります:
- DBサービスとEmailサービスは、それぞれ
DbConnectionとSmtpCredentialsという追加のパラメータを取ります。これらを何らかの方法で渡す必要がありますが、機能の中核部分ではないため隠しておけると良いでしょう。 - DBサービスとEmailサービスは、それらが非純粋であり、
InfrastructureErrorで失敗する可能性があることを示すAsyncResultを返します。これは役立ちますが、(Readerなどの)他のエフェクトと組み合わせると面倒になることも意味します。 - ロガーは、非純粋であっても、
AsyncResultを返しません。ドメインコードの途中でロガーを使用しても、ビジネスロジックに影響を与えるべきではありません。
グローバルなロガーとこれらのサービスのデフォルト実装が利用可能であると仮定します。
アプローチ #1: 依存関係の保持
Section titled “アプローチ #1: 依存関係の保持”最初の実装では、抽象化やパラメータ化を試みずに、すべての依存関係を直接使用します。
注意点:
- インフラストラクチャサービスは
AsyncResultを返すため、asyncResultコンピュテーション式を使用してコードを書きやすく、理解しやすくします。 - 決定(
if currentProfile <> newProfile)と非純粋なコードが混在しています。
let updateCustomerProfile (newProfile:Profile) = let dbConnection = defaultDbService.NewDbConnection() let smtpCredentials = defaultSmtpCredentials asyncResult { let! currentProfile = defaultDbService.QueryProfile dbConnection newProfile.UserId
if currentProfile <> newProfile then globalLogger.Info("Updating Profile") do! defaultDbService.UpdateProfile dbConnection newProfile
if currentProfile.EmailAddress <> newProfile.EmailAddress then let emailMessage = { To = newProfile.EmailAddress Body = "Please verify your email" } globalLogger.Info("Sending email") do! defaultEmailService.SendChangeNotification smtpCredentials emailMessage }最初の投稿で説明したように、小さなスクリプトの場合、またはプロトタイプやスケッチを迅速に組み立てるために使用される場合は、このアプローチで問題ないと思います。ただし、このコードは適切にテストするのが非常に難しいので、さらに複雑になる場合は、純粋なコードと非純粋なコードから分離するようにリファクタリングすることを強くお勧めします。これは「依存関係の排除」アプローチです。
アプローチ #2: 依存関係の排除
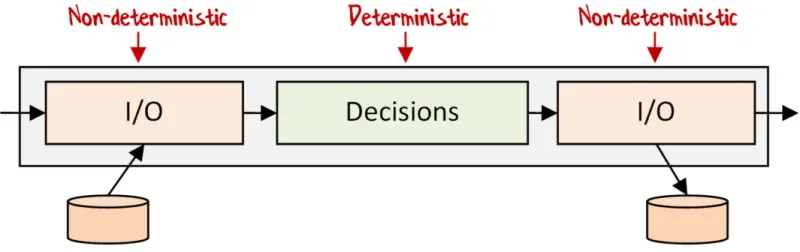
Section titled “アプローチ #2: 依存関係の排除”以前の投稿で「依存関係の排除」について説明したとき、この図を使用して最終目標を示しました。つまり、純粋で決定的なコードを、非純粋で非決定的なコードから分離することです。
それでは、このアプローチを例に適用してみましょう。決定事項は次の通りです:
- 何もしない
- データベースのみを更新する
- データベースを更新し、確認メールも送信する
では、その決定を型としてエンコードしましょう。
type Decision = | NoAction | UpdateProfileOnly of Profile | UpdateProfileAndNotify of Profile * EmailMessageそして今、コードの純粋な意思決定部分は、次のように実装できます:
let updateCustomerProfile (newProfile:Profile) (currentProfile:Profile) = if currentProfile <> newProfile then globalLogger.Info("Updating Profile") if currentProfile.EmailAddress <> newProfile.EmailAddress then let emailMessage = { To = newProfile.EmailAddress Body = "Please verify your email" } globalLogger.Info("Sending email") UpdateProfileAndNotify (newProfile, emailMessage) else UpdateProfileOnly newProfile else NoActionこの実装では、データベースからの読み取りは行いません。代わりに、currentProfileをパラメータとして渡します。
また、データベースに書き込みません。代わりに、後続の非純粋な部分に何をすべきかを伝えるために、Decision型を返します。
その結果、このコードは非常にテストしやすくなります。
ロガーはパラメータとして渡されていないことに注意してください。globalLoggerをそのまま使用しています。場合によっては、ロギングはグローバル変数へのアクセスに関するルールの例外となる可能性があると思います。もしこれが気になるなら、次のセクションでそれをパラメータに変えましょう!
これでコードの「純粋な」意思決定部分が完了したので、トップレベルのコードを実装できます。ご覧のとおり、望みどおりに、非純粋/純粋/非純粋のサンドイッチ構造になりました。
let updateCustomerProfile (newProfile:Profile) = let dbConnection = defaultDbService.NewDbConnection() let smtpCredentials = defaultSmtpCredentials asyncResult { // ----------- 非純粋 ---------------- let! currentProfile = defaultDbService.QueryProfile dbConnection newProfile.UserId
// ----------- 純粋 ---------------- let decision = Pure.updateCustomerProfile newProfile currentProfile
// ----------- 非純粋 ---------------- match decision with | NoAction -> () | UpdateProfileOnly profile -> do! defaultDbService.UpdateProfile dbConnection profile | UpdateProfileAndNotify (profile,emailMessage) -> do! defaultDbService.UpdateProfile dbConnection profile do! defaultEmailService.SendChangeNotification smtpCredentials emailMessage }このようにコードを2つの部分に分割することは非常に簡単で、多くの利点があります。ですから、「依存関係の排除」は常に最初に行うべきリファクタリングです。
この投稿の残りの部分では、追加のテクニックを使用する場合でも、意思決定部分とIOを使用する部分は分離したままにします。
アプローチ #3: 依存関係のパラメータ化
Section titled “アプローチ #3: 依存関係のパラメータ化”これで、純粋なコードと非純粋なコードを分離しましたが、ロガーだけは例外で、純粋なコードから簡単に切り離すことができません。
このロガーの問題に対処しましょう。少なくとも、テストを容易にする最も簡単な方法は、次のように、ロガーを純粋なコアにパラメータとして渡すことです:
let updateCustomerProfile (logger:ILogger) (newProfile:Profile) (currentProfile:Profile) = if currentProfile <> newProfile then logger.Info("Updating Profile") if currentProfile.EmailAddress <> newProfile.EmailAddress then ... logger.Info("Sending email") UpdateProfileAndNotify (newProfile, emailMessage) else UpdateProfileOnly newProfile else NoAction必要であれば、トップレベルの非純粋なコード内のサービスもパラメータ化できます。インフラストラクチャサービスが多い場合は、それらを単一の型にまとめるのが一般的です:
type IServices = { Logger : ILogger DbService : IDbService EmailService : IEmailService }この型のパラメータを、以下に示すようにトップレベルのコードに渡すことができます。以前にdefaultDbServiceを直接使用していたすべての場所で、現在はservicesパラメータを使用しています。loggerはサービスから抽出され、上記で実装した純粋関数にパラメータとして渡されることに注意してください。
let updateCustomerProfile (services:IServices) (newProfile:Profile) = let dbConnection = services.DbService.NewDbConnection() let smtpCredentials = defaultSmtpCredentials let logger = services.Logger
asyncResult { // ----------- 非純粋 ---------------- let! currentProfile = services.DbService.QueryProfile dbConnection newProfile.UserId
// ----------- 純粋 ---------------- let decision = Pure.updateCustomerProfile logger newProfile currentProfile
// ----------- 非純粋 ---------------- match decision with | NoAction -> () | UpdateProfileOnly profile -> do! services.DbService.UpdateProfile dbConnection profile | UpdateProfileAndNotify (profile,emailMessage) -> do! services.DbService.UpdateProfile dbConnection profile do! services.EmailService.SendChangeNotification smtpCredentials emailMessage }このようにservicesパラメータを渡すことで、サービスのモック化や実装の変更が容易になります。これは特別な専門知識を必要としない簡単なリファクタリングなので、「依存関係の排除」と同様に、コードのテストが困難になってきた場合は、これも最初にお勧めするリファクタリングの1つです。
アプローチ #4a: OOスタイルの依存関係の注入
Section titled “アプローチ #4a: OOスタイルの依存関係の注入”OO(オブジェクト指向)スタイルで依存関係を渡すには、通常、オブジェクトが作成されるときにコンストラクタに渡します。これは関数型ファーストな設計のデフォルトのアプローチではありませんが、C#から使用されるF#コードを書いている場合や、この種の依存関係の注入を期待するC#フレームワーク内で作業している場合は、この手法を使用すべきです。
// 依存関係を受け入れるコンストラクタを持つクラスを定義するtype MyWorkflow (services:IServices) =
member this.UpdateCustomerProfile (newProfile:Profile) = let dbConnection = services.DbService.NewDbConnection() let smtpCredentials = defaultSmtpCredentials let logger = services.Logger
asyncResult { // ----------- 非純粋 ---------------- let! currentProfile = services.DbService.QueryProfile dbConnection newProfile.UserId
// ----------- 純粋 ---------------- let decision = Pure.updateCustomerProfile logger newProfile currentProfile
// ----------- 非純粋 ---------------- match decision with | NoAction -> () | UpdateProfileOnly profile -> do! services.DbService.UpdateProfile dbConnection profile | UpdateProfileAndNotify (profile,emailMessage) -> do! services.DbService.UpdateProfile dbConnection profile do! services.EmailService.SendChangeNotification smtpCredentials emailMessage }ご覧のとおり、UpdateCustomerProfileメソッドには明示的なservicesパラメータがなく、代わりにクラス全体のスコープ内にあるservicesフィールドを使用しています。
利点は、メソッド呼び出し自体がよりシンプルになることです。欠点は、メソッドがクラスのコンテキストに依存するようになり、リファクタリングや単独でのテストが難しくなることです。
アプローチ #4b: Readerモナド
Section titled “アプローチ #4b: Readerモナド”依存関係の注入を遅らせるFP(関数型プログラミング)の同等物は、Reader型と、それに関連するツール(readerコンピュテーション式など)です。
Readerモナドの詳細については、以前の投稿を参照してください。
次に示すのは、コードの純粋な部分を、ILoggerを環境として含むReaderを返すように書いたものです。
let updateCustomerProfile (newProfile:Profile) (currentProfile:Profile) = reader { let! (logger:ILogger) = Reader.ask
let decision = if currentProfile <> newProfile then logger.Info("Updating Profile") if currentProfile.EmailAddress <> newProfile.EmailAddress then let emailMessage = { To = newProfile.EmailAddress Body = "Please verify your email" } logger.Info("Sending email") UpdateProfileAndNotify (newProfile, emailMessage) else UpdateProfileOnly newProfile else NoAction
return decision }updateCustomerProfileの戻り値の型は、まさに必要なReader<ILogger,Decision>です。
トップレベルのコードからReaderを実行するには、次のようにします。
let updateCustomerProfile (services:IServices) (newProfile:Profile) = let logger = services.Logger
asyncResult { // ----------- 非純粋 ---------------- let! currentProfile = ...
// ----------- 純粋 ---------------- let decision = Pure.updateCustomerProfile newProfile currentProfile |> Reader.run logger
// ----------- 非純粋 ---------------- match decision with ... などトップレベルの依存関係にもReaderを使用する
Section titled “トップレベルの依存関係にもReaderを使用する”どうしてもReaderを使用したい場合は、ロギングのような「エフェクトのない」依存関係を純粋なコード内で隠すためだけに使用することをお勧めします。
AsyncResultなど、さまざまな種類のエフェクトを返す非純粋なコードにReaderを使用すると、非常に厄介になる可能性があります。
これを説明するために、非純粋なコードを2つの新しい関数に分割してみましょう。各関数はReaderを返します。
最初の関数は、データベースからプロファイルを読み取ります。Readerの環境としてIServicesが必要であり、AsyncResult<Profile,InfrastructureError>を返します。したがって、全体的な戻り値の型はReader<IServices, AsyncResult<Profile,InfrastructureError>>となり、これはかなり厄介です。
let getProfile (userId:UserId) = reader { let! (services:IServices) = Reader.ask let dbConnection = services.DbService.NewDbConnection() return services.DbService.QueryProfile dbConnection userId }2番目の関数は、決定を処理し、必要に応じてデータベース内のプロファイルを更新します。繰り返しますが、Readerの環境としてIServicesが必要であり、AsyncResultでラップされたunitを返します。したがって、全体的な戻り値の型はReader<IServices, AsyncResult<unit,InfrastructureError>>になります。
let handleDecision (decision:Decision) = reader { let! (services:IServices) = Reader.ask let dbConnection = services.DbService.NewDbConnection() let smtpCredentials = defaultSmtpCredentials let action = asyncResult { match decision with | NoAction -> () | UpdateProfileOnly profile -> do! services.DbService.UpdateProfile dbConnection profile | UpdateProfileAndNotify (profile,emailMessage) -> do! services.DbService.UpdateProfile dbConnection profile do! services.EmailService.SendChangeNotification smtpCredentials emailMessage } return action }複数の異なるエフェクト(この場合はReader、Async、およびResult)を同時に扱うのはかなり骨が折れます。Haskellのような言語にはいくつかの回避策がありますが、F#はこれを実行するように設計されていません。最も簡単な方法は、結合されたエフェクトのセットに対してカスタムのコンピュテーション式を書くことです。AsyncとResultのエフェクトは、多くの場合一緒に使用されるため、特別なasyncResultコンピュテーション式を用意するのが理にかなっています。しかし、Readerを組み合わせに加えると、readerAsyncResultのようなコンピュテーション式が必要になります。
以下の実装では、それをあえてやりませんでした。代わりに、全体的なasyncResult式の中で、必要に応じて各コンポーネント関数のReaderを実行するだけにしました。見苦しいですが、機能します。
let updateCustomerProfile (newProfile:Profile) = reader { let! (services:IServices) = Reader.ask let getLogger services = services.Logger
return asyncResult { // ----------- 非純粋 ---------------- let! currentProfile = getProfile newProfile.UserId |> Reader.run services
// ----------- 純粋 ---------------- let decision = Pure.updateCustomerProfile newProfile currentProfile |> Reader.withEnv getLogger |> Reader.run services
// ----------- 非純粋 ---------------- do! (handleDecision decision) |> Reader.run services } }アプローチ #5: 依存関係の解釈
Section titled “アプローチ #5: 依存関係の解釈”最後に、前の投稿で説明したインタープリターアプローチの適用について見ていきます。
プログラムを書くためには、次のことが必要になります。
- 使用したい命令セットを定義します。これらは関数ではなく、データ構造になります。
- 前の投稿で定義した汎用の「Program」ライブラリで使用できるように、これらの各命令セットに対して
IInstructionを実装します。 - 命令を作成しやすくするためのヘルパー関数を作成します。
- 以上で、
programコンピュテーション式を使用してコードを書くことができます。
それが完了したら、プログラムを解釈する必要があります:
- 命令セットごとにサブインタープリターを作成します。
- 次に、必要に応じてサブインタープリターを呼び出す、プログラム全体のトップレベルインタープリターを作成します。
これを行うのを、コードの純粋な部分のみにするか、または非純粋な部分も含めるかは選択できます。まずは純粋な部分だけを実行することから始めましょう。
純粋なコンポーネントの開発
Section titled “純粋なコンポーネントの開発”まず、純粋なコードのための命令セットを定義する必要があります。現時点で必要なのはロギングだけです。したがって、次のものが必要です:
- 各ロギングアクションに対応するケースを含む
LoggerInstruction型 IInstructionとその関連するMapメソッドの実装- さまざまな命令を作成するためのヘルパー関数
コードは次のとおりです:
type LoggerInstruction<'a> = | LogInfo of string * next:(unit -> 'a) | LogError of string * next:(unit -> 'a) interface IInstruction<'a> with member this.Map f = match this with | LogInfo (str,next) -> LogInfo (str,next >> f) | LogError (str,next) -> LogError (str,next >> f) :> IInstruction<_>
// computation expression内で使用するヘルパーlet logInfo str = Instruction (LogInfo (str,Stop))let logError str = Instruction (LogError (str,Stop))この命令セットを使用すると、以前の実装で必要だったロガーパラメータを抽象化して、純粋な部分を記述できます。
let updateCustomerProfile (newProfile:Profile) (currentProfile:Profile) = if currentProfile <> newProfile then program { do! logInfo("Updating Profile") if currentProfile.EmailAddress <> newProfile.EmailAddress then let emailMessage = { To = newProfile.EmailAddress Body = "Please verify your email" } do! logInfo("Sending email") return UpdateProfileAndNotify (newProfile, emailMessage) else return UpdateProfileOnly newProfile } else program { return NoAction }updateCustomerProfileの戻り値の型は、単なるProgram<Decision>です。特定のILoggerはどこにも記述されていません!
メインのif/then/else式の各分岐にサブprogramがあることに注意してください。コンピュテーション式内でlet!とdo!をネストするルールは、特に直感的ではなく、“This construct may only be used within computation expressions”のようなエラーが発生する可能性があります。正しく動作させるためには、少し調整が必要な場合があります。
非純粋なコンポーネントの開発
Section titled “非純粋なコンポーネントの開発”もしすべての直接的なI/O呼び出しを解釈されたものに置き換えたい場合は、それらの命令セットを作成する必要があります。したがって、IDbServiceおよびIEmailServiceインターフェースの代わりに、次のような命令型を使用します:
type DbInstruction<'a> = | QueryProfile of UserId * next:(Profile -> 'a) | UpdateProfile of Profile * next:(unit -> 'a) interface IInstruction<'a> with member this.Map f = match this with | QueryProfile (userId,next) -> QueryProfile (userId,next >> f) | UpdateProfile (profile,next) -> UpdateProfile (profile, next >> f) :> IInstruction<_>
type EmailInstruction<'a> = | SendChangeNotification of EmailMessage * next:(unit-> 'a) interface IInstruction<'a> with member this.Map f = match this with | SendChangeNotification (message,next) -> SendChangeNotification (message,next >> f) :> IInstruction<_>そして、コンピュテーション式内で使用するヘルパーは次のとおりです。
let queryProfile userId = Instruction (QueryProfile(userId,Stop))let updateProfile profile = Instruction (UpdateProfile(profile,Stop))let sendChangeNotification message = Instruction (SendChangeNotification(message,Stop))シェルプログラムの作成
Section titled “シェルプログラムの作成”Readerの実装と同様に、システムを3つのコンポーネントに分割します:
getProfile。データベースからプロファイルを読み取る非純粋な部分。updateCustomerProfile。上記で実装した純粋な部分。handleDecision。決定を処理し、必要に応じてデータベース内のプロファイルを更新する非純粋な部分。
QueryProfile命令を作成するだけで実際には何も実行しないqueryProfileヘルパーを使用して、getProfileの実装を次に示します。
let getProfile (userId:UserId) :Program<Profile> = program { return! queryProfile userId }handleDecisionの実装を次に示します。NoActionのケースでは、Programでラップされたunitを返したいことに注意してください。それはまさにprogram.Zero()の機能です。program { return() }を使用して、同じ効果を得ることもできました。
let handleDecision (decision:Decision) :Program<unit> = match decision with | NoAction -> program.Zero() | UpdateProfileOnly profile -> updateProfile profile | UpdateProfileAndNotify (profile,emailMessage) -> program { do! updateProfile profile do! sendChangeNotification emailMessage }これらの3つの関数があれば、トップレベル関数を簡単に実装できます。
let updateCustomerProfile (newProfile:Profile) = program { let! currentProfile = getProfile newProfile.UserId let! decision = Pure.updateCustomerProfile newProfile currentProfile do! handleDecision decision }非常にすっきりしています。 AsyncResultsはどこにもありません!そのため、以前に実装したReaderバージョンよりもクリーンになります。
サブインタープリターの作成
Section titled “サブインタープリターの作成”しかし、ここで難しい部分、サブインタープリターとトップレベルインタープリターの実装について説明します。
これは、インフラストラクチャサービスがすべてAsyncResultを返すという事実によって、さらに複雑になります。行うことはすべて、そのコンテキストに持ち上げる必要があります。
まず、DbInstructionのインタープリターを見ていきましょう。(以下のコードでは、どの値がAsyncResultsであるかを示すために「AS」サフィックスを追加しました。)
何が起こっているのかを理解するために、まず1つの命令、QueryProfileのインタープリターから始めましょう。
| QueryProfile (userId, next) -> let profileAS = defaultDbService.QueryProfile dbConnection userId let newProgramAS = (AsyncResult.map next) profileAS interpret newProgramASまず、インフラストラクチャサービスを呼び出します。これはAsyncResultを返します。
let profileAS = defaultDbService.QueryProfile dbConnection userIdそれから、next関数を呼び出して、次に解釈するProgramを取得します。ただし、next関数はAsyncResultでは機能しないため、AsyncResult.mapを使用して、機能する関数に「持ち上げる」必要があります。それ以降は、profileASで呼び出して、AsyncResultでラップされた新しいProgramを取得できます。
let newProgramAS = (AsyncResult.map next) profileAS最後に、プログラムを解釈できます。通常、インタープリターはProgram<'a>を受け取り、'aを返します。
しかし、AsyncResultがすべてを汚染しているため、interpret関数はAsyncResult<Program<'a>>を受け取り、AsyncResult<'a>を返す必要があります。
interpret newProgramAS // returns an AsyncResult<'a,InfrastructureError>interpretDbInstructionの完全な実装を次に示します
let interpretDbInstruction (dbConnection:DbConnection) interpret inst = match inst with | QueryProfile (userId, next) -> let profileAS = defaultDbService.QueryProfile dbConnection userId let newProgramAS = (AsyncResult.map next) profileAS interpret newProgramAS | UpdateProfile (profile, next) -> let unitAS = defaultDbService.UpdateProfile dbConnection profile let newProgramAS = (AsyncResult.map next) unitAS interpret newProgramASまた、interpretDbInstructionがdbConnectionをパラメータとして取ることに注意してください。呼び出し元は、それを渡す必要があります。
EmailInstructionのインタープリター実装も同様です。
LoggerInstructionインタープリターについては、ロガーサービスがAsyncResultを使用しないため、多少調整する必要があります。この場合、通常の方法でnextを呼び出して新しいプログラムを作成しますが、その後、asyncResult.Returnを使用して結果をAsyncResultに「持ち上げ」ます。
let interpretLogger interpret inst = match inst with | LogInfo (str, next) -> globalLogger.Info str let newProgramAS = next() |> asyncResult.Return interpret newProgramAS | LogError (str, next) -> ...トップレベルインタープリターの作成
Section titled “トップレベルインタープリターの作成”各命令セットのサブインタープリターを構築しましたが、まだ安心できません。トップレベルインタープリターもかなり複雑です!
以下がそのコードです:
let interpret program = // 1. 追加のパラメータを取得し、部分適用してすべてのインタープリターが // 一貫した形状を持つようにする let smtpCredentials = defaultSmtpCredentials let dbConnection = defaultDbService.NewDbConnection() let interpretDbInstruction' = interpretDbInstruction dbConnection let interpretEmailInstruction' = interpretEmailInstruction smtpCredentials
// 2. 再帰的なループ関数を定義する。シグネチャは次のとおり: // AsyncResult<Program<'a>,InfrastructureError>) -> AsyncResult<'a,InfrastructureError> let rec loop programAS = asyncResult { let! program = programAS return! match program with | Instruction inst -> match inst with | :? LoggerInstruction<Program<_>> as inst -> interpretLogger loop inst | :? DbInstruction<Program<_>> as inst -> interpretDbInstruction' loop inst | :? EmailInstruction<Program<_>> as inst -> interpretEmailInstruction' loop inst | _ -> failwithf "unknown instruction type %O" (inst.GetType()) | Stop value -> value |> asyncResult.Return }
// 3. ループを開始する let initialProgram = program |> asyncResult.Return loop initialProgram3つのセクションに分解しました。順番に見ていきましょう。
まず、追加のパラメータ(smtpCredentialsとdbConnection)を取得し、これらのパラメータを部分適用したインタープリターのローカルなバリアントを作成します。
これにより、すべてのインタープリター関数が同じ「形状」になります。厳密には必要ありませんが、少しクリーンになると思います。
次に、ローカルな「loop」関数を定義します。これが実際のインタープリターループです。このようにローカル関数を使用することには多くの利点があります。
- スコープ内にある値を再利用できます。この場合、解釈プロセス全体で同じ
dbConnectionを再利用できます。 - メインの
interpretとは異なるシグネチャを持つことができます。この場合、ループは通常のProgramではなく、AsyncResultsでラップされたProgramを受け入れます。
loop関数の内部では、Programの2つのケースを処理します:
Instructionケースの場合、loop関数はサブインタープリターを呼び出し、次のステップを再帰的に解釈するために自身を渡します。Stopケースの場合、通常の値を取り、asyncResult.Returnを使用してAsyncResultにラップします。
最後に、一番下でループを開始します。入力としてAsyncResultが必要なので、ここでもasyncResult.Returnを使用して初期入力プログラムを持ち上げる必要があります。
インタープリターが利用可能になったので、最上位の関数を完成させることができます。その動作は次のとおりです。
Shell.updateCustomerProfileを呼び出して、Programを返します。- 次に、
interpretを使用してそのプログラムを解釈して、AsyncResultを返します。 - 次に、その
AsyncResultを実行して、最終的な応答を取得します(場合によっては、HTTPコードなどに変換することもあります)。
let updateCustomerProfileApi (newProfile:Profile) = Shell.updateCustomerProfile newProfile |> interpret |> Async.RunSynchronouslyインタープリターアプローチのレビュー
Section titled “インタープリターアプローチのレビュー”前の投稿で見たように、そしてここで見たように、インタープリターアプローチは、すべての依存関係が隠蔽された非常にクリーンなコードになります。IOの扱いや、積み重ねられた複数のエフェクト(例:ResultをラップするAsync)を処理することなど、厄介なことはすべて、なくなっているか、むしろ、インタープリターに押し付けられています。
しかし、そのクリーンなコードに到達するには、多くの追加作業が必要でした。このプログラムでは5つの命令しか必要としませんでしたが、それらをサポートするために約100行の追加コードを書く必要がありました!そして、それはAsyncResultという1種類のエフェクトのみを扱う、インタープリターの単純なバージョンでした。さらに、実際には、トランポリンを追加してスタックオーバーフローを回避する必要もあるかもしれず、コードはさらに複雑になります。一般的に、ほとんどの状況では、これは手間がかかりすぎると言えるでしょう。
では、これが良い考えとなるのはいつでしょうか?
- ユースケースとして、他の人が使用するためのDSLやライブラリを作成する必要があり、かつ命令の数が少ない場合は、「フロントエンド」の使用の単純さが「バックエンド」インタープリターの複雑さを上回るかもしれません。
- I/Oリクエストのバッチ処理、以前の結果のキャッシュなどの最適化を行う必要がある場合。プログラムと解釈を分離することで、クリーンなフロントエンドを維持しながら、これらの最適化を舞台裏で行うことができます。
これらの要件はTwitterに適用され、Twitterのエンジニアリングチームは、これに似たことを行うStitchと呼ばれるライブラリを開発しました。このビデオで優れた説明がされていますし、こちらの投稿もあります。なお、Facebookエンジニアリングも、同じ理由で開発されたHaxlと呼ばれる同様のライブラリを持っています。
この投稿では、6つの異なるテクニックを同じ例に適用しました。どれが一番気に入りましたか?
各アプローチに対する私の個人的な意見は次のとおりです:
- 依存関係の保持 は、小さなスクリプトやテストする必要がない場合には問題ありません。
- 依存関係の排除 は、良い考えであり、常に使用すべきです(決定が少なく、I/Oが多いワークフローにはいくつかの例外があります)。
- 依存関係のパラメータ化 は、一般的に、純粋なコードをテスト可能にするための良い考えです。I/Oの多い「端」でインフラストラクチャサービスをパラメータ化することは必須ではありませんが、多くの場合、役立ちます。
- OOスタイルの依存関係の注入 は、OOスタイルのC#またはOOスタイルのフレームワークとやり取りする場合は、使用すべきです。自分で苦労する必要はありません!
- Readerモナド は、ここで紹介した他のテクニックに対する明確な利点が見られない限り、お勧めする手法ではありません。
- 依存関係の解釈 も、他のどのテクニックもうまく機能しない特定のユースケースがない限り、お勧めする手法ではありません。
私の意見に関係なく、すべての手法はあなたのツールボックスに入れておくと役立ちます。特に、実際にはあまり使用しない場合でも、Readerとインタープリターの実装がどのように機能するかを理解しておくのは良いことです。
この投稿のソースコードは、このgist で公開されています。