map, apply, bind, sequence の実際的な使い方
この投稿は、一連の投稿の5番目です。
最初の2つの投稿では、ジェネリックデータ型を扱うためのいくつかのコア関数、map、bindなどについて説明しました。
3番目の投稿では、「アプリカティブ」と「モナディック」のスタイルの違い、そして値と関数を一貫性のあるものにするための持ち上げ方について議論しました。
前回の投稿では、高次の値のリストを扱う方法として、traverseとsequenceを紹介しました。
この投稿では、これまでに議論してきたすべてのテクニックを使用する実用的な例を検討することで、締めくくりとします。
シリーズの内容
Section titled “シリーズの内容”このシリーズで触れる様々な関数へのショートカットリストです。
- パート1:高次の世界への持ち上げ
- パート2:世界をまたぐ関数の合成方法
- パート3:コア関数の実際的な使い方
- パート4:リストと高次の値の混合
- パート5:すべてのテクニックを使用する実世界の例
- パート6:独自の高次の世界を設計する
- パート7:まとめ
パート5:すべてのテクニックを使用する実世界の例
Section titled “パート5:すべてのテクニックを使用する実世界の例”例:Webサイトのリストをダウンロードして処理する
Section titled “例:Webサイトのリストをダウンロードして処理する”この例は、3番目の投稿の冒頭で述べたものの変形版になります。
- Webサイトのリストが与えられたら、最大のホームページを持つサイトを見つけるアクションを作成します。
これを手順に分解しましょう。
まず、URLをアクションのリストに変換する必要があります。各アクションでは、ページをダウンロードしてコンテンツのサイズを取得します。
次に、最大のコンテンツを見つける必要がありますが、そのためには、アクションのリストをサイズのリストを含む単一のアクションに変換する必要があります。
そこで、traverseまたはsequenceの出番です。
始めましょう!
ダウンローダー
Section titled “ダウンローダー”まず、ダウンローダーを作成する必要があります。組み込みのSystem.Net.WebClientクラスを使用したいところですが、何らかの理由でタイムアウトのオーバーライドが許可されていません。
後のテストで不正なURIに対して小さなタイムアウトを設定したいので、オーバーライドできないのは重大です。
1つのトリックは、WebClientをサブクラス化して、リクエストを構築するメソッドをインターセプトすることです。これがそのコードです。
// ミリ秒の単位を定義type [<Measure>] ms
/// カスタムのタイムアウト設定可能なWebClientの実装type WebClientWithTimeout(timeout:int<ms>) = inherit System.Net.WebClient()
override this.GetWebRequest(address) = let result = base.GetWebRequest(address) result.Timeout <- int timeout resultタイムアウト値に単位を使用していることに注意してください。秒とミリ秒を区別することができるので、単位は非常に価値があると思います。 かつて、2000ミリ秒ではなく2000秒にタイムアウトを設定してしまったことがあり、二度とそのような間違いはしたくありません!
次のコードは、ドメインの型を定義しています。URLとサイズを一緒に保持できるようにしたいと思います。タプルを使用することもできますが、 ドメインのモデル化に型を使用することを提唱しています。ドキュメンテーションのためだけでも、そうすべきだと思います。
// ダウンロードしたページのコンテンツtype UriContent = UriContent of System.Uri * string
// ダウンロードしたページのコンテンツサイズtype UriContentSize = UriContentSize of System.Uri * intこれは些細な例では過剰かもしれませんが、より重要なプロジェクトでは非常に価値があると思います。
次は、ダウンロードを行うコードです。
/// 指定されたUriのページのコンテンツを取得する/// Uri -> Async<Result<UriContent>>let getUriContent (uri:System.Uri) = async { use client = new WebClientWithTimeout(1000<ms>) // 1秒のタイムアウト try printfn " [%s] 開始..." uri.Host let! html = client.AsyncDownloadString(uri) printfn " [%s] ...完了" uri.Host let uriContent = UriContent (uri, html) return (Result.Success uriContent) with | ex -> printfn " [%s] ...例外" uri.Host let err = sprintf "[%s] %A" uri.Host ex.Message return Result.Failure [err] }注意点:
- .NETライブラリは、さまざまなエラーで例外をスローするので、それをキャッチして
Failureに変換しています。 use client =セクションでは、ブロックの最後でクライアントが正しく破棄されるようにしています。- 全体の操作は
asyncワークフローでラップされており、let! html = client.AsyncDownloadStringでダウンロードが非同期で行われます。 - トレース用に
printfnを追加しましたが、これはこの例のためだけです。実際のコードでは、もちろんこのようなことはしません!
先に進む前に、このコードをインタラクティブにテストしてみましょう。まず、結果を出力するためのヘルパーが必要です。
let showContentResult result = match result with | Success (UriContent (uri, html)) -> printfn "成功: [%s] 最初の100文字: %s" uri.Host (html.Substring(0,100)) | Failure errs -> printfn "失敗: %A" errsそれでは、正常なサイトで試してみましょう。
System.Uri ("https://google.com")|> getUriContent|> Async.RunSynchronously|> showContentResult
// [google.com] 開始...// [google.com] ...完了// 成功: [google.com] 最初の100文字: <!doctype html><html itemscope="" itemtype="https://schema.org/WebPage" lang="ja"><head><meta contそして、不正なサイトでも試してみましょう。
System.Uri ("https://example.bad")|> getUriContent|> Async.RunSynchronously|> showContentResult
// [example.bad] 開始...// [example.bad] ...例外// 失敗: ["[example.bad] "リモート名 'example.bad' を解決できませんでした。""]map、apply、bindでAsync型を拡張する
Section titled “map、apply、bindでAsync型を拡張する”この時点で、Asyncの世界を扱うことになるのは分かっているので、先に進む前に、4つのコア関数が使えることを確認しましょう。
module Async =
let map f xAsync = async { // xAsyncの中身を取得 let! x = xAsync // 関数を適用し、結果を持ち上げる return f x }
let retn x = async { // xをAsyncに持ち上げる return x }
let apply fAsync xAsync = async { // 2つの非同期を並列で開始 let! fChild = Async.StartChild fAsync let! xChild = Async.StartChild xAsync
// 結果を待つ let! f = fChild let! x = xChild
// 結果に関数を適用する return f x }
let bind f xAsync = async { // xAsyncの中身を取得 let! x = xAsync // 関数を適用するが、結果を持ち上げない // fはAsyncを返すため return! f x }これらの実装は素直です。
asyncワークフローを使ってAsyncの値を扱っています。mapのlet!構文は、Asyncからコンテンツを抽出します(つまり、実行して結果を待ちます)。map、retn、applyのreturn構文は、値をreturnを使ってAsyncに持ち上げます。apply関数は、与えられた2つの処理を並列に実行します。これは、fork/joinと呼ばれるパターンを使っています。 もし、let! fChild = ...の後にlet! xChild = ...と書いていたら、 モナディックな順次処理になってしまい、私の意図とは異なる結果になっていたでしょう。bindのreturn!構文は、値がすでに持ち上げられていて、それにreturnを呼び出さないないことを意味します。
ダウンロードしたページのサイズを取得する
Section titled “ダウンロードしたページのサイズを取得する”ダウンロードの手順の次に、結果をUriContentSizeに変換するプロセスに進みましょう。
/// UriContentからUriContentSizeを作成する/// UriContent -> Result<UriContentSize>let makeContentSize (UriContent (uri, html)) = if System.String.IsNullOrEmpty(html) then Result.Failure ["空のページ"] else let uriContentSize = UriContentSize (uri, html.Length) Result.Success uriContentSize入力のhtmlがnullまたは空の場合は、これをエラーとして扱い、そうでない場合はUriContentSizeを返します。
これで2つの関数ができました。それらを1つの「UriからUriContentSizeを取得する」関数に組み合わせたいと思います。問題は、出力と入力が一致しないことです。
getUriContentはUri -> Async<Result<UriContent>>makeContentSizeはUriContent -> Result<UriContentSize>
解決策は、makeContentSizeをUriContentを入力とする関数から、Async<Result<UriContent>>を入力とする関数に変換することです。
どうすればいいのでしょうか。
まず、Result.bindを使って、a -> Result<b>関数をResult<a> -> Result<b>関数に変換します。
この場合、UriContent -> Result<UriContentSize>はResult<UriContent> -> Result<UriContentSize>になります。
次に、Async.mapを使って、a -> b関数をAsync<a> -> Async<b>関数に変換します。
この場合、Result<UriContent> -> Result<UriContentSize>はAsync<Result<UriContent>> -> Async<Result<UriContentSize>>になります。
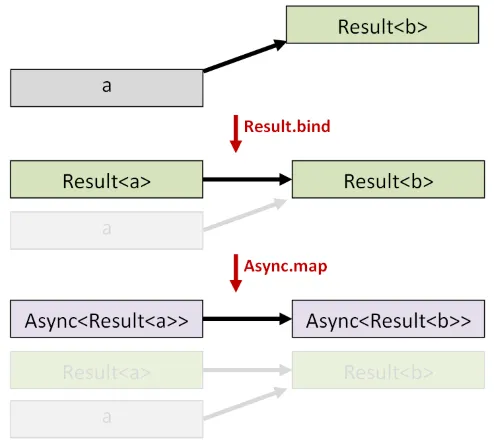
そして、正しい種類の入力を受け取れるようになったので、getUriContentと合成することができます。
/// 指定されたUriのページのコンテンツのサイズを取得する/// Uri -> Async<Result<UriContentSize>>let getUriContentSize uri = getUriContent uri |> Async.map (Result.bind makeContentSize)これは複雑な型シグネチャですが、これからもっと悪化していくでしょう!このような時に型推論に本当に感謝します。
もう一度テストしてみましょう。まず、結果をフォーマットするためのヘルパーを用意します。
let showContentSizeResult result = match result with | Success (UriContentSize (uri, len)) -> printfn "成功: [%s] コンテンツのサイズは %i" uri.Host len | Failure errs -> printfn "失敗: %A" errsそして、正常なサイトで試してみましょう。
System.Uri ("https://google.com")|> getUriContentSize|> Async.RunSynchronously|> showContentSizeResult
// [google.com] 開始...// [google.com] ...完了//成功: [google.com] コンテンツのサイズは 44293そして、不正なサイトでも。
System.Uri ("https://example.bad")|> getUriContentSize|> Async.RunSynchronously|> showContentSizeResult
// [example.bad] 開始...// [example.bad] ...例外//失敗: ["[example.bad] "リモート名 'example.bad' を解決できませんでした。""]リストから最大のサイズを取得する
Section titled “リストから最大のサイズを取得する”このプロセスの最後のステップは、最大のページサイズを見つけることです。
それは簡単です。いったんUriContentSizeのリストが得られれば、List.maxByを使って最大のものを簡単に見つけることができます。
/// リストから最大のUriContentSizeを取得する/// UriContentSize list -> UriContentSizelet maxContentSize list =
// UriContentSizeからlenフィールドを抽出する let contentSize (UriContentSize (_, len)) = len
// maxByを使って最大のものを見つける list |> List.maxBy contentSizeすべてをまとめる
Section titled “すべてをまとめる”これで、すべてのピースを組み立てる準備ができました。以下のアルゴリズムを使用します。
- URLのリストを用意する
- 文字列のリストを
Uriのリストに変換する(Uri list) Uriのリストをアクションのリストに変換する(Async<Result<UriContentSize>> list)- 次に、スタックの上位2つの部分を入れ替える必要があります。つまり、
List<Async>をAsync<List>に変換します。
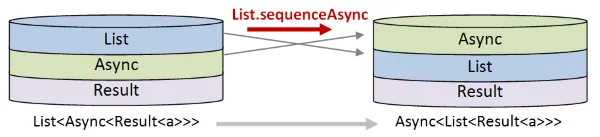
- 次に、スタックの下位2つの部分を入れ替える必要があります。つまり、
List<Result>をResult<List>に変換します。 しかし、スタックの下位2つの部分はAsyncでラップされているので、これを行うにはAsync.mapを使用する必要があります。
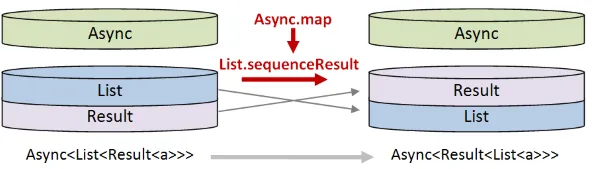
- 最後に、一番下の
ListにList.maxByを使用して、それを単一の値に変換する必要があります。つまり、List<UriContentSize>をUriContentSizeに変換します。 しかし、スタックの一番下はResultでラップされ、さらにAsyncでラップされているので、これを行うにはAsync.mapとResult.mapを使用する必要があります。
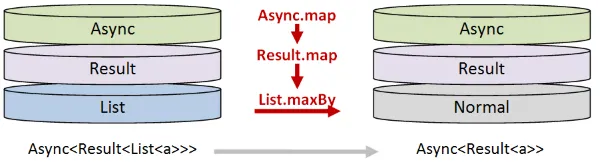
完全なコードは以下の通りです。
/// Webサイトのリストから最大のページサイズを取得するlet largestPageSizeA urls = urls // 文字列のリストをUriのリストに変換する // (F# v4では、System.Uriを直接呼び出すことができます!) |> List.map (fun s -> System.Uri(s))
// UriのリストをAsync<Result<UriContentSize>> listに変換する |> List.map getUriContentSize
// Async<Result<UriContentSize>> listを // Async<Result<UriContentSize> list>に変換する |> List.sequenceAsyncA
// Async<Result<UriContentSize> list>を // Async<Result<UriContentSize list>>に変換する |> Async.map List.sequenceResultA
// 内部のリストで最大のものを見つけて // Async<Result<UriContentSize>>を取得する |> Async.map (Result.map maxContentSize)この関数のシグネチャはstring list -> Async<Result<UriContentSize>>で、これはまさに私たちが望んでいたものです!
ここでは、2つのsequence関数が使われています。sequenceAsyncAとsequenceResultAです。
実装は、これまでの議論から期待されるものですが、コードを見せておきましょう。
module List =
/// アプリカティブスタイルを使用して、リストに対してAsync生成関数をマップし、 /// 新しいAsyncを取得する /// ('a -> Async<'b>) -> 'a list -> Async<'b list> let rec traverseAsyncA f list =
// アプリカティブ関数を定義する let (<*>) = Async.apply let retn = Async.retn
// "cons"関数を定義する let cons head tail = head :: tail
// リストを右畳み込みする let initState = retn [] let folder head tail = retn cons <*> (f head) <*> tail
List.foldBack folder list initState
/// "list<Async>"を"Async<list>"に変換し、 /// applyを使用して結果を収集する let sequenceAsyncA x = traverseAsyncA id x
/// アプリカティブスタイルを使用して、リストに対してResult生成関数をマップし、 /// 新しいResultを取得する /// ('a -> Result<'b>) -> 'a list -> Result<'b list> let rec traverseResultA f list =
// アプリカティブ関数を定義する let (<*>) = Result.apply let retn = Result.Success
// "cons"関数を定義する let cons head tail = head :: tail
// リストを右畳み込みする let initState = retn [] let folder head tail = retn cons <*> (f head) <*> tail
List.foldBack folder list initState
/// "list<Result>"を"Result<list>"に変換し、 /// applyを使用して結果を収集する let sequenceResultA x = traverseResultA id xタイマーの追加
Section titled “タイマーの追加”ダウンロードにかかる時間がシナリオによってどう変わるのか見てみましょう。 そこで、ある関数を一定の回数実行し、平均を取るための小さなタイマーを作成しましょう。
/// 関数fをcountN回繰り返し実行し、1回あたりの時間を表示するlet time countN label f =
let stopwatch = System.Diagnostics.Stopwatch()
// 開始時に完全なGCを行うが、その後は行わない // 各繰り返しでガベージを収集できるようにする System.GC.Collect()
printfn "=======================" printfn "%s" label printfn "======================="
let mutable totalMs = 0L
for iteration in [1..countN] do stopwatch.Restart() f() stopwatch.Stop() printfn "#%2i 経過時間:%6ims " iteration stopwatch.ElapsedMilliseconds totalMs <- totalMs + stopwatch.ElapsedMilliseconds
let avgTimePerRun = totalMs / int64 countN printfn "%s: 1回あたりの平均時間:%6ims " label avgTimePerRunいよいよダウンロード
Section titled “いよいよダウンロード”それでは、実際のサイトをダウンロードしてみましょう。
2つのサイトのリストを定義します。「良い」リストは、すべてのサイトにアクセスできるはずです。「悪い」リストには、無効なサイトが含まれています。
let goodSites = [ "https://google.com" "https://bbc.co.uk" "https://fsharp.org" "https://microsoft.com" ]
let badSites = [ "https://example.com/nopage" "https://bad.example.com" "https://verybad.example.com" "https://veryverybad.example.com" ]まず、良いサイトのリストでlargestPageSizeAを10回実行してみましょう。
let f() = largestPageSizeA goodSites |> Async.RunSynchronously |> showContentSizeResulttime 10 "largestPageSizeA_Good" f出力は次のようになります。
[google.com] 開始...[bbc.co.uk] 開始...[fsharp.org] 開始...[microsoft.com] 開始...[bbc.co.uk] ...完了[fsharp.org] ...完了[google.com] ...完了[microsoft.com] ...完了
成功: [bbc.co.uk] コンテンツのサイズは 108983largestPageSizeA_Good: 1回あたりの平均時間: 533msダウンロードが並列に行われていることがすぐにわかります。すべてのダウンロードが最初のダウンロードの完了を待たずに開始されています。
では、いくつかのサイトが不正な場合はどうでしょうか?
let f() = largestPageSizeA badSites |> Async.RunSynchronously |> showContentSizeResulttime 10 "largestPageSizeA_Bad" f出力は次のようになります。
[example.com] 開始...[bad.example.com] 開始...[verybad.example.com] 開始...[veryverybad.example.com] 開始...[verybad.example.com] ...例外[veryverybad.example.com] ...例外[example.com] ...例外[bad.example.com] ...例外
失敗: [ "[example.com] "リモート サーバーがエラーを返しました: (404) 見つかりません。""; "[bad.example.com] "リモート名 'bad.example.com' を解決できませんでした。""; "[verybad.example.com] "リモート名 'verybad.example.com' を解決できませんでした。""; "[veryverybad.example.com] "リモート名 'veryverybad.example.com' を解決できませんでした。""]
largestPageSizeA_Bad: 1回あたりの平均時間: 2252msここでも、すべてのダウンロードが並列に行われており、4つのエラーすべてが返されています。
largestPageSizeAには、マップとシーケンスが連続して並んでいます。つまり、リストが3回反復され、非同期が2回マップされることになります。
以前にも述べたように、私は明快さをマイクロ最適化よりも優先します。証拠がない限り、これは気にしません。
しかし、もしやりたいのであれば、何ができるか見てみましょう。
以下は、コメントを取り除いた元のバージョンです。
let largestPageSizeA urls = urls |> List.map (fun s -> System.Uri(s)) |> List.map getUriContentSize |> List.sequenceAsyncA |> Async.map List.sequenceResultA |> Async.map (Result.map maxContentSize)最初の2つのList.mapは組み合わせることができます。
let largestPageSizeA urls = urls |> List.map (fun s -> System.Uri(s) |> getUriContentSize) |> List.sequenceAsyncA |> Async.map List.sequenceResultA |> Async.map (Result.map maxContentSize)map-sequenceはtraverseに置き換えることができます。
let largestPageSizeA urls = urls |> List.traverseAsyncA (fun s -> System.Uri(s) |> getUriContentSize) |> Async.map List.sequenceResultA |> Async.map (Result.map maxContentSize)そして、最後に2つのAsync.mapも組み合わせることができます。
let largestPageSizeA urls = urls |> List.traverseAsyncA (fun s -> System.Uri(s) |> getUriContentSize) |> Async.map (List.sequenceResultA >> Result.map maxContentSize)個人的には、ここまでやると可読性が下がってしまうと思います。私は元のバージョンの方が好みですね。
ついでに言えば、マップを自動的にマージしてくれる「ストリーム」ライブラリを使うのも一つの方法です。
F#では、Nessos Streamsが優れています。
ストリームと標準のseqの違いを示したブログ記事もあります。
モナディックなダウンロード
Section titled “モナディックなダウンロード”モナディックなスタイルでダウンロードロジックを再実装し、それがどのような違いをもたらすか見てみましょう。
まず、モナディックなダウンローダーが必要です。
let largestPageSizeM urls = urls |> List.map (fun s -> System.Uri(s)) |> List.map getUriContentSize |> List.sequenceAsyncM // <= "M"バージョン |> Async.map List.sequenceResultM // <= "M"バージョン |> Async.map (Result.map maxContentSize)このバージョンでは、モナディックなsequence関数を使用しています(実装は省略します。期待通りのものです)。
良いサイトのリストでlargestPageSizeMを10回実行し、アプリカティブなバージョンとの違いがあるかどうか見てみましょう。
let f() = largestPageSizeM goodSites |> Async.RunSynchronously |> showContentSizeResulttime 10 "largestPageSizeM_Good" f出力は次のようになります。
[google.com] 開始... [google.com] ...完了 [bbc.co.uk] 開始... [bbc.co.uk] ...完了 [fsharp.org] 開始... [fsharp.org] ...完了 [microsoft.com] 開始... [microsoft.com] ...完了
成功: [bbc.co.uk] コンテンツのサイズは 108695largestPageSizeM_Good: 1回あたりの平均時間: 955ms今回は大きな違いがあります。ダウンロードが直列に行われていることが明らかです。各ダウンロードは、前のダウンロードが完了してから開始されています。
その結果、1回あたりの平均時間は955msで、アプリカティブなバージョンのほぼ2倍になっています。
では、サイトの一部が不正な場合はどうでしょうか?何が起こると予想されますか?モナディックなので、最初のエラーの後、残りのサイトはスキップされるはずですよね? 実際にそうなるか見てみましょう!
let f() = largestPageSizeM badSites |> Async.RunSynchronously |> showContentSizeResulttime 10 "largestPageSizeM_Bad" f出力は次のようになります。
[example.com] 開始...[example.com] ...例外[bad.example.com] 開始...[bad.example.com] ...例外[verybad.example.com] 開始...[verybad.example.com] ...例外[veryverybad.example.com] 開始...[veryverybad.example.com] ...例外
失敗: ["[example.com] "リモート サーバーがエラーを返しました: (404) 見つかりません。""]largestPageSizeM_Bad: 1回あたりの平均時間: 2371ms予想外の結果でした!すべてのサイトが直列に訪問されましたが、最初のサイトでエラーが発生していました。 しかし、その場合、すべてのエラーではなく、最初のエラーのみが返されるのはなぜでしょうか?
何が問題だったのかわかりますか?
実装がうまくいかなかった理由は、AsyncのチェーンとResultのチェーンが独立していたためです。
デバッガでステップ実行すると、何が起こっているのかがわかります。
- リスト内の最初の
Asyncが実行され、失敗しました。 - 次の
AsyncでAsync.bindが使用されました。しかし、Async.bindにはエラーの概念がないため、次のAsyncが実行され、別の失敗が発生しました。 - このようにして、すべての
Asyncが実行され、失敗のリストが生成されました。 - この失敗のリストは、
Result.bindを使ってトラバースされました。もちろん、bindのために、最初の失敗のみが処理され、残りは無視されました。 - 最終的な結果は、すべての
Asyncが実行されたが、最初の失敗のみが返されたということです。
2つの世界を1つとして扱う
Section titled “2つの世界を1つとして扱う”根本的な問題は、AsyncのリストとResultのリストを別々のトラバース対象として扱っていることです。
しかし、それでは、Resultが失敗しても、次のAsyncが実行されるかどうかに影響を与えません。
そこで、AsyncとResultをを結びつけて、失敗した結果が次のAsyncを実行するかどうかを決定するようにしたいと思います。
そのためには、AsyncとResultを1つの型として扱う必要があります。想像力をたくましくして、AsyncResultと呼ぶことにしましょう。
それらが1つの型であれば、bindは次のようになります。
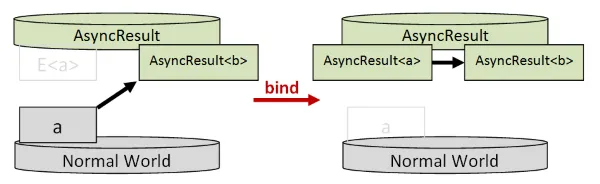
つまり、前の値が次の値を決定するということです。
また、「入れ替え」がはるかに簡単になります。

AsyncResult型の定義
Section titled “AsyncResult型の定義”さて、AsyncResult型とそれに関連するmap、return、apply、bind関数を定義しましょう。
/// 型エイリアス(オプション)type AsyncResult<'a> = Async<Result<'a>>
/// AsyncResultの関数module AsyncResult =module AsyncResult =
let map f = f |> Result.map |> Async.map
let retn x = x |> Result.retn |> Async.retn
let apply fAsyncResult xAsyncResult = fAsyncResult |> Async.bind (fun fResult -> xAsyncResult |> Async.map (fun xResult -> Result.apply fResult xResult))
let bind f xAsyncResult = async { let! xResult = xAsyncResult match xResult with | Success x -> return! f x | Failure err -> return (Failure err) }注意点:
- 型エイリアスはオプションです。コードでは
Async<Result<'a>>を直接使えば、うまく動作します。重要なのは、概念的にAsyncResultが別の型であるということです。 bindの実装は新しいものです。継続関数fは2つの世界をまたいでおり、'a -> Async<Result<'b>>というシグネチャを備えています。- 内側の
Resultが成功した場合、結果で継続関数fが評価されます。return!構文は、戻り値がすでに持ち上げられていることを意味します。 - 内側の
Resultが失敗した場合、失敗をAsyncに持ち上げる必要があります。
- 内側の
traverseおよびsequence関数の定義
Section titled “traverseおよびsequence関数の定義”bindとreturnが整ったところで、AsyncResultに適したtraverseとsequence関数を作成しましょう。
module List =
/// モナディックスタイルを使用して、リストに対してAsyncResult生成関数をマップし、 /// 新しいAsyncResultを取得する /// ('a -> AsyncResult<'b>) -> 'a list -> AsyncResult<'b list> let rec traverseAsyncResultM f list =
// モナディック関数を定義する let (>>=) x f = AsyncResult.bind f x let retn = AsyncResult.retn
// "cons"関数を定義する let cons head tail = head :: tail
// リストを右畳み込みする let initState = retn [] let folder head tail = f head >>= (fun h -> tail >>= (fun t -> retn (cons h t) ))
List.foldBack folder list initState
/// "list<AsyncResult>"を"AsyncResult<list>"に変換し、 /// bindを使用して結果を収集する let sequenceAsyncResultM x = traverseAsyncResultM id xダウンロード関数の定義とテスト
Section titled “ダウンロード関数の定義とテスト”最後に、largestPageSize関数は、シーケンスが1つだけになったので、よりシンプルになりました。
let largestPageSizeM_AR urls = urls |> List.map (fun s -> System.Uri(s) |> getUriContentSize) |> List.sequenceAsyncResultM |> AsyncResult.map maxContentSize良いサイトのリストでlargestPageSizeM_ARを10回実行し、アプリカティブなバージョンとの違いがあるかどうか見てみましょう。
let f() = largestPageSizeM_AR goodSites |> Async.RunSynchronously |> showContentSizeResulttime 10 "largestPageSizeM_AR_Good" f出力は次のようになります。
[google.com] 開始...[google.com] ...完了[bbc.co.uk] 開始...[bbc.co.uk] ...完了[fsharp.org] 開始...[fsharp.org] ...完了[microsoft.com] 開始...[microsoft.com] ...完了
成功: [bbc.co.uk] コンテンツのサイズは 108510largestPageSizeM_AR_Good: 1回あたりの平均時間: 1026ms今回も、ダウンロードは直列に行われています。そして再び、1回あたりの時間は、アプリカティブなバージョンのほぼ2倍になっています。
さて、待望の瞬間がやってきました!最初の不正なサイトの後、ダウンロードをスキップするでしょうか?
let f() = largestPageSizeM_AR badSites |> Async.RunSynchronously |> showContentSizeResulttime 10 "largestPageSizeM_AR_Bad" f出力は次のようになります。
[example.com] 開始... [example.com] ...例外
失敗: ["[example.com] "リモート サーバーがエラーを返しました: (404) 見つかりません。""]largestPageSizeM_AR_Bad: 1回あたりの平均時間: 117ms成功です!最初の不正なサイトでのエラーによって残りのダウンロードがスキップされました。実行時間が短くなったことがそれを裏付けています。
この投稿では、小さな実用的な例を見てきました。
この例から、map、apply、bind、traverse、sequenceが単なる学問的な抽象概念ではなく、ツールベルトに欠かせない重要なツールであることがわかったと思います。
次の投稿では、別の実用的な例を見ていきますが、今度は独自の高次の世界を作ることになります。 では、そのときまで!