traverseとsequenceを理解する
この投稿は連載記事の一部です。
最初の2つの投稿では、ジェネリックデータ型を扱うためのコア関数について説明しました。map、bindなどです。
前回の投稿では、「アプリカティブ」と「モナディック」スタイルについて議論し、値と関数を互いに一貫性のある形で高次の世界に持ち上げる方法を説明しました。
今回の投稿では、よくある問題を見ていきます。高次の値のリストを扱う方法です。
シリーズの内容
Section titled “シリーズの内容”このシリーズで言及される様々な関数へのショートカットリストです。
- パート1:高次の世界への持ち上げ
- パート2:世界をまたぐ関数の合成方法
- パート3:コア関数の実際的な使い方
- パート4:リストと高次の値の混合
- パート5:すべてのテクニックを使用する実世界の例
- パート6:独自の高次の世界を設計する
- パート7:まとめ
パート4:リストと高次の値の混合
Section titled “パート4:リストと高次の値の混合”よくある問題は、高次の値のリストやコレクションをどう扱うかです。
いくつかの例を見てみましょう。
-
例1:
string -> int optionというシグネチャを持つparseInt関数があり、文字列のリストがあるとします。すべての文字列を一度に解析したいとします。mapを使えば文字列のリストをオプションのリストに変換できます。しかし、必要なのは「オプションのリスト」ではなく、「リストのオプション」です。 つまり、解析された整数のリストを、失敗した場合にオプションでラップしたものです。 -
例2:
CustomerId -> Result<Customer>というシグネチャを持つreadCustomerFromDb関数があるとします。 この関数は、レコードが見つかって返された場合はSuccessを、そうでない場合はFailureを返します。そして、CustomerIdのリストがあり、すべての顧客を一度に読み取りたいとします。mapを使えばIDのリストを結果のリストに変換できます。しかし、必要なのはResult<Customer>のリストではなく、Customer listを含むResultです。 エラーが発生した場合、ResultはFailureケースになってほしいのです。 -
例3:
Uri -> Async<string>というシグネチャを持つfetchWebPage関数があるとします。この関数は、要求に応じてページの内容をダウンロードするタスクを返します。 そして、Uriのリストがあり、すべてのページを一度にフェッチしたいとします。mapを使えばUriのリストをAsyncのリストに変換できます。しかし、必要なのはAsyncのリストではありません。 文字列のリストを含む単一のAsyncが求められています。
オプション生成関数のマッピング
Section titled “オプション生成関数のマッピング”まず最初のケースの解決策を考え出し、それを他のケースに一般化できるかどうか見てみましょう。
一般的な解決方法は以下の通りです。
- まず、
mapを使ってstringのリストをOption<int>のリストに変換します。 - 次に、
Option<int>のリストをOption<int list>に変換する関数を作ります。
しかし、これにはリストを2回通過する必要があります。1回の通過でできないでしょうか?
できます!リストの構築には「cons」関数を使います。F#では::演算子がこれに相当します。cons関数は、リストの先頭に新しい要素を追加する働きをします。
cons操作をOptionの世界に持ち上げると、Option.applyを使って高次のconsで先頭のOptionを末尾のOptionに結合できます。
let (<*>) = Option.applylet retn = Some
let rec mapOption f list = let cons head tail = head :: tail match list with | [] -> retn [] | head::tail -> retn cons <*> (f head) <*> (mapOption f tail)注意:::は関数ではないため、このコンテキストでは使用できません。また、List.Consはタプルを引数に取るため、ここでは適していません。そのため、cons関数を明示的に定義しました。
実装を図で表すと次のようになります。
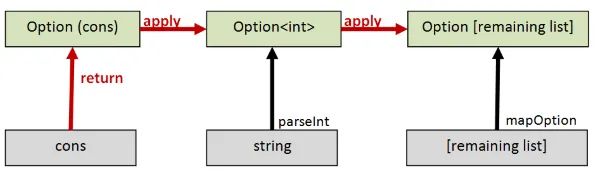
この動作の仕組みがわからない場合は、このシリーズの最初の投稿の apply に関するセクションを読んでください。
また、実装で Some を使用するのではなく、明示的に retn を定義して使用していることに注目してください。次のセクションでその理由がわかります。
では、テストしてみましょう!
let parseInt str = match (System.Int32.TryParse str) with | true,i -> Some i | false,_ -> None// string -> int option
let good = ["1";"2";"3"] |> mapOption parseInt// Some [1; 2; 3]
let bad = ["1";"x";"y"] |> mapOption parseInt// Noneまず、string -> int option 型の parseInt を定義します。この関数は既存の .NET ライブラリを利用しています。
mapOption を使って適切な値のリストに対して実行すると、オプションの中にリストがある Some [1; 2; 3] が得られます。これが期待通りの結果です。
そして、一部の値が不正なリストを使用すると、結果全体に対して None が得られます。
Result生成関数のマッピング
Section titled “Result生成関数のマッピング”これを繰り返しますが、今度は以前のバリデーション例で使用した Result 型を使います。
mapResult 関数は次のようになります。
let (<*>) = Result.applylet retn = Success
let rec mapResult f list = let cons head tail = head :: tail match list with | [] -> retn [] | head::tail -> retn cons <*> (f head) <*> (mapResult f tail)ここでも Success を使用するのではなく、明示的に retn を定義しています。そのおかげで、mapResult と mapOption のコード本体が全く同じになっています!
では、parseInt を Option ではなく Result を返すように変更しましょう。
let parseInt str = match (System.Int32.TryParse str) with | true,i -> Success i | false,_ -> Failure [str + " is not an int"]次に、テストを再度実行します。今回は失敗した場合、より詳細な情報が得られるようになっています。
let good = ["1";"2";"3"] |> mapResult parseInt// Success [1; 2; 3]
let bad = ["1";"x";"y"] |> mapResult parseInt// Failure ["x is not an int"; "y is not an int"]汎用的なmapXXX関数は作成できるか?
Section titled “汎用的なmapXXX関数は作成できるか?”mapOptionとmapResultの実装は全く同じコードです。
唯一の違いは、異なるretnと<*>関数(それぞれOptionとResultに対するもの)を使用している点です。
このことから、次のような疑問が生じます。
高次の型ごとにmapResult、mapOptionなどの特定の実装を作る代わりに、すべての高次型で動作する、完全に汎用的なバージョンのmapXXXを作成できないでしょうか?
すぐに思いつくアプローチは、これら2つの関数を追加のパラメータとして渡すことです。以下のようになります。
let rec mapE (retn,ap) f list = let cons head tail = head :: tail let (<*>) = ap
match list with | [] -> retn [] | head::tail -> (retn cons) <*> (f head) <*> (mapE retn ap f tail)しかし、これにはいくつかの問題があります。まず、このコードはF#ではコンパイルできません! さらに、仮にコンパイルできたとしても、同じ2つのパラメータがどこでも確実に渡されるようにしたいところです。
この問題に対処するため、次のような方法が考えられます。2つのパラメータを含むレコード構造を作成し、高次の世界の型ごとに1つのインスタンスを作成します。
type Applicative<'a,'b> = { retn: 'a -> E<'a> apply: E<'a->'b> -> E<'a> -> E<'b> }
// Optionに適用する関数let applOption = {retn = Option.Some; apply=Option.apply}
// Resultに適用する関数let applResult = {retn = Result.Success; apply=Result.apply}Applicativeレコードのインスタンス(たとえばappl)を、汎用的なmapE関数への追加パラメータとして使用します。
let rec mapE appl f list = let cons head tail = head :: tail let (<*>) = appl.apply let retn = appl.retn
match list with | [] -> retn [] | head::tail -> (retn cons) <*> (f head) <*> (mapE retn ap f tail)使用時には、使用したい特定のapplicativeインスタンスを渡します。
// Option特有のバージョンを構築let mapOption = mapE applOption
// 使用例let good = ["1";"2";"3"] |> mapOption parseInt残念ながら、上記のアプローチも、少なくともF#では機能しません。定義したApplicative型はコンパイルできないのです。これは、F#が「高カインド型」をサポートしていないためです。
つまり、Applicative型をジェネリック型でパラメータ化することができず、具体的な型でしかパラメータ化できません。
「高カインド型」をサポートするHaskellのような言語では、ここで定義したApplicative型は「型クラス」に似ています。
さらに、型クラスを使用すると、関数を明示的に渡す必要がなくなります。コンパイラが代わりに処理してくれます。
実は、F#でも静的型制約を使用して同様の効果を得る巧妙(そしてハッキー)な方法があります。 ここでは詳しく説明しませんが、FSharpxライブラリでその使用例を見ることができます。
このような抽象化の代替案は、扱いたい高次の世界ごとにmapXXX関数を作成することです。
mapOption、mapResult、mapAsyncなどです。
個人的には、この直接的なアプローチでも十分実用的だと考えています。実際、日常的に扱う高次の世界はそれほど多くありません。抽象化は失われますが、明示性が得られます。 これはチームで作業する際にしばしば有用です。
では、これらのmapXXX関数、別名traverseを見ていきましょう。
traverse / mapM 関数
Section titled “traverse / mapM 関数”一般的な名前: mapM, traverse, for
一般的な演算子: なし
機能: 世界をまたぐ関数を、コレクションで動作するように変換します
シグネチャ: (a->E<b>) -> a list -> E<b list> (またはlistが他のコレクション型に置き換わったバリエーション)
前述のように、XXXがアプリカティブな世界(applyとreturnを持つ世界)を表すmapXXX関数のセットを定義できます。
これらのmapXXX関数は、世界をまたぐ関数をコレクションで動作するように変換します。
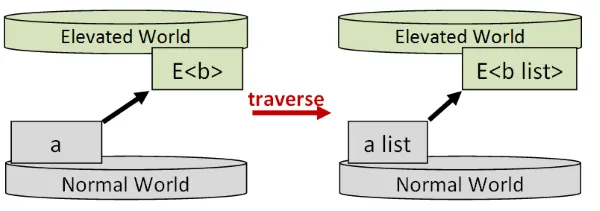
また、先ほど述べたように、言語が型クラスをサポートしている場合、単一の実装(mapMまたはtraverseと呼ばれる)で済みます。
ここからは、この一般的な概念をtraverseと呼ぶことにします。これがmapとは異なることを明確にするためです。
Map vs. Traverse
Section titled “Map vs. Traverse”mapとtraverseの違いを理解するのは難しいかもしれません。そこで、図を使って説明してみましょう。
まず、「高次の」世界が「通常の」世界の上に位置するというアナロジーを使用して、視覚的な表記法を導入します。
これらの高次の世界のほとんど(実際にはほぼすべて!)にはapplyとreturn関数があります。これらを「アプリカティブな世界」と呼びます。
例としてOption、Result、Asyncなどがあります。
また、高次の世界の一部にはtraverse関数があります。traverse関数を持つ世界を「走査可能(Traversable)な世界」と呼びます。典型的な例としてListを使うことにします。
走査可能な世界が上にある場合、List<a>のような型が生成され、
アプリカティブな世界が上にある場合、Result<a>のような型が生成されます。

重要:ここでは一貫性のためにList<_>という構文を「リストの世界」を表すために使用しています。これは.NETのListクラスとは異なります!
F#では、これは不変のlist型で実装されます。
しかし、これからは同じ「スタック」の中で両方の種類の高次の世界を扱うことになります。
走査可能な世界をアプリカティブな世界の上に積み重ねると、List<Result<a>>のような型が生成されます。
あるいは、アプリカティブな世界を走査可能な世界の上に積み重ねると、Result<List<a>>のような型が生成されます。

この表記法を用いて、様々な種類の関数がどのように表現されるか確認していきましょう。
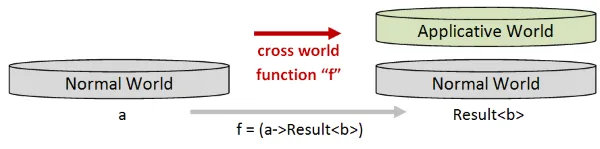
まず、a -> Result<b>のような単純な世界をまたぐ関数から始めましょう。ここで、目標の世界はアプリカティブな世界です。
図では、入力は通常の世界(左側)で、出力(右側)は通常の世界の上に積み重ねられたアプリカティブな世界です。
次に、通常のa値のリストがあり、a -> Result<b>のような関数を使用して各a値を変換するためにmapを使用すると、
結果もリストになりますが、内容はa値の代わりにResult<b>値になります。
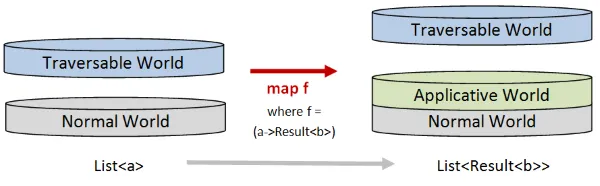
traverseの場合、効果は全く異なります。
a値のリストをその関数で変換するためにtraverseを使用すると、
出力はリストではなくResultになります。そして、Resultの内容はList<b>になります。
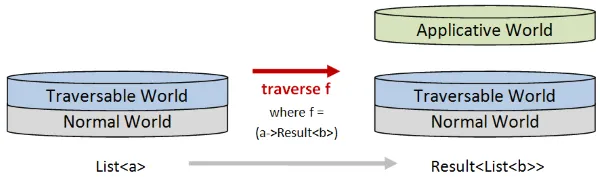
つまり、traverseでは、Listは通常の世界に付属したままで、アプリカティブな世界(Resultなど)が上部に追加されます。
これらの説明は非常に抽象的に聞こえるかもしれませんが、実際には非常に有用な技法です。この使用例については後ほど見ていきます。
traverseのアプリカティブバージョンとモナディックバージョン
Section titled “traverseのアプリカティブバージョンとモナディックバージョン”traverseは、アプリカティブスタイルまたはモナディックスタイルで実装できることがわかっています。そのため、しばしば2つの別々の実装から選択することになります。
アプリカティブバージョンは通常Aで終わり、モナディックバージョンはMで終わります。これは覚えやすいですね!
これがどのように機能するか、お馴染みのResult型を使って見てみましょう。
まず、アプリカティブアプローチとモナディックアプローチの両方を使用してtraverseResultを実装します。
module List =
/// Result生成関数をリストにマップして新しいResultを取得します /// アプリカティブスタイルを使用 /// ('a -> Result<'b>) -> 'a list -> Result<'b list> let rec traverseResultA f list =
// アプリカティブ関数を定義 let (<*>) = Result.apply let retn = Result.Success
// "cons"関数を定義 let cons head tail = head :: tail
// リストをループ処理 match list with | [] -> // 空の場合、[]をResultに持ち上げる retn [] | head::tail -> // そうでない場合、fを使用してheadをResultに持ち上げ // 残りのリストの持ち上げられたバージョンとconsする retn cons <*> (f head) <*> (traverseResultA f tail)
/// Result生成関数をリストにマップして新しいResultを取得します /// モナディックスタイルを使用 /// ('a -> Result<'b>) -> 'a list -> Result<'b list> let rec traverseResultM f list =
// モナディック関数を定義 let (>>=) x f = Result.bind f x let retn = Result.Success
// "cons"関数を定義 let cons head tail = head :: tail
// リストをループ処理 match list with | [] -> // 空の場合、[]をResultに持ち上げる retn [] | head::tail -> // そうでない場合、fを使用してheadをResultに持ち上げ // 次にtraverseを使用してtailをResultに持ち上げ // そしてheadとtailをconsして返す f head >>= (fun h -> traverseResultM f tail >>= (fun t -> retn (cons h t) ))アプリカティブバージョンは、先ほど使用した実装と同じです。
モナディックバージョンは、最初の要素に関数fを適用し、それをbindに渡します。
モナディックスタイルの常として、結果が不正ならリストの残りの部分はスキップされます。
一方、結果が適切なら、リストの次の要素が処理され、以降も同様です。その後、結果が再びconsで結合されます。
注意:これらの実装はデモンストレーション用のみです!これらの実装は末尾再帰ではないため、大きなリストでは失敗します!
では、2つの関数をテストして、どのように異なるか見てみましょう。まず、parseInt関数が必要です:
/// 整数を解析してResultを返します/// string -> Result<int>let parseInt str = match (System.Int32.TryParse str) with | true,i -> Result.Success i | false,_ -> Result.Failure [str + " is not an int"]適切な値(すべて解析可能)のリストを渡すと、両方の実装で結果は同じになります。
// リストにラップされた文字列を渡す// (アプリカティブバージョン)let goodA = ["1"; "2"; "3"] |> List.traverseResultA parseInt// 整数のリストを含むResultが返される// Success [1; 2; 3]
// リストにラップされた文字列を渡す// (モナディックバージョン)let goodM = ["1"; "2"; "3"] |> List.traverseResultM parseInt// 整数のリストを含むResultが返される// Success [1; 2; 3]しかし、不正な値を含むリストを渡すと、結果は異なります。
// リストにラップされた文字列を渡す// (アプリカティブバージョン)let badA = ["1"; "x"; "y"] |> List.traverseResultA parseInt// 整数のリストを含むResultが返される// Failure ["x is not an int"; "y is not an int"]
// リストにラップされた文字列を渡す// (モナディックバージョン)let badM = ["1"; "x"; "y"] |> List.traverseResultM parseInt// 整数のリストを含むResultが返される// Failure ["x is not an int"]アプリカティブバージョンはすべてのエラーを返しますが、モナディックバージョンは最初のエラーのみを返します。
foldを使用したtraverseの実装
Section titled “foldを使用したtraverseの実装”前述のとおり、「ゼロから」の実装は末尾再帰ではなく、大きなリストでは失敗します。 もちろん、コードをより複雑にすることでこの問題を解決できます。
一方、コレクション型にListのような「右畳み込み」関数がある場合、それを使用して実装をより簡単、高速、そして安全にできます。
個人的には、できるだけfoldやその関連関数を活用するようにしています。そうすることで、末尾再帰を正しく実装する心配をする必要がなくなります!
では、List.foldBackを使用してtraverseResultを再実装してみましょう。コードをできるだけ似た状態に保ちつつ、
再帰関数を作成する代わりに、リストのループ処理を畳み込み関数に委ねています。
/// Result生成関数をリストにマップして新しいResultを取得します/// アプリカティブスタイルを使用/// ('a -> Result<'b>) -> 'a list -> Result<'b list>let traverseResultA f list =
// アプリカティブ関数を定義 let (<*>) = Result.apply let retn = Result.Success
// "cons"関数を定義 let cons head tail = head :: tail
// リストを右から畳み込む let initState = retn [] let folder head tail = retn cons <*> (f head) <*> tail
List.foldBack folder list initState
/// Result生成関数をリストにマップして新しいResultを取得/// モナディックスタイルを使用/// ('a -> Result<'b>) -> 'a list -> Result<'b list>let traverseResultM f list =
// モナディック関数を定義 let (>>=) x f = Result.bind f x let retn = Result.Success
// "cons"関数を定義 let cons head tail = head :: tail
// リストを右から畳み込む let initState = retn [] let folder head tail = f head >>= (fun h -> tail >>= (fun t -> retn (cons h t) ))
List.foldBack folder list initStateこのアプローチはすべてのコレクションクラスで機能するわけではないことに注意してください。一部の型には右畳み込みがないため、
traverseは異なる方法で実装する必要があります。
リスト以外の型についてはどうか?
Section titled “リスト以外の型についてはどうか?”これらの例ではすべてコレクション型としてlist型を使用しています。他の型に対してもtraverseを実装できるでしょうか?
はい、できます。たとえば、Optionは1要素のリストと考えることができ、同じ手法を使用できます。
例として、Optionに対するtraverseResultAの実装を見てみましょう。
module Option =
/// Result生成関数をOptionにマップして新しいResultを取得します /// ('a -> Result<'b>) -> 'a option -> Result<'b option> let traverseResultA f opt =
// アプリカティブ関数を定義 let (<*>) = Result.apply let retn = Result.Success
// オプションをループ処理 match opt with | None -> // 空の場合、NoneをResultに持ち上げる retn None | Some x -> // 値をResultに持ち上げる (retn Some) <*> (f x)これで、文字列をOptionでラップし、それにparseIntを適用できます。OptionのResultではなく、スタックを反転させてResultのOptionを取得します。
// Optionでラップされた文字列を渡すlet good = Some "1" |> Option.traverseResultA parseInt// Optionを含むResultが返される// Success (Some 1)解析できない文字列を渡すと、失敗になります。
// Optionでラップされた文字列を渡すlet bad = Some "x" |> Option.traverseResultA parseInt// Optionを含むResultが返される// Failure ["x is not an int"]Noneを渡すと、Noneを含むSuccessが返されます!
// Optionでラップされた文字列を渡すlet goodNone = None |> Option.traverseResultA parseInt// Optionを含むResultが返される// Success (None)この最後の結果は一見驚くかもしれませんが、こう考えてください。解析は失敗していないので、Failureは全くありませんでした。
Traversable(走査可能)
Section titled “Traversable(走査可能)”mapXXXやtraverseXXXのような関数を実装できる型はTraversableと呼ばれます。たとえば、コレクション型はTraversableですし、他にもいくつかあります。
前述のように、型クラスを持つ言語では、Traversable型はtraverseの実装を1つだけ持てば十分です。
しかし、型クラスのない言語では、Traversable型は高次の型ごとに1つの実装が必要になります。
また、これまで作成してきた汎用関数とは異なり、traverseを実装するには、(コレクション内の)操作対象の型が適切なapplyとreturn関数を持っている必要があることに注意してください。
つまり、内部の型がApplicativeでなければなりません。
正しいtraverse実装の性質
Section titled “正しいtraverse実装の性質”常のことですが、traverseの正しい実装は、どの高次の世界で作業していても成り立つべきいくつかの性質を持っています。
これらは「Traversable則」と呼ばれます。
Traversableはジェネリックなデータ型コンストラクタであるE<T> と、
これらの法則に従う関数のセット(traverseまたはtraverseXXX)として定義されます。
これらの法則は以前のものと似ています。たとえば、恒等関数が正しくマップされること、合成が保持されること、などです。
sequence関数
Section titled “sequence関数”一般的な名前: sequence
一般的な演算子: なし
機能: 高次の値のリストを、リストを含む高次の値に変換します
シグネチャ: E<a> list -> E<a list> (またはリストが他のコレクション型に置き換わったバリエーション)
前述のように、traverse関数を使用して、アプリカティブ型(Resultなど)を生成する関数がある場合にmapの代替として使用できます。
しかし、List<Result>を与えられて、それをResult<List>に変更する必要がある場合はどうでしょうか。つまり、スタック内の世界の順序を入れ替える必要がある場合です。
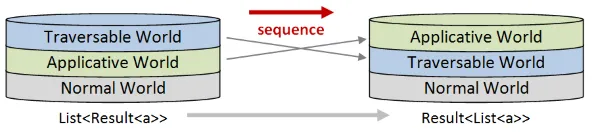
ここでsequenceが役立ちます。まさにこれがsequenceの機能だからです! sequence関数は「レイヤーを入れ替え」ます。
入れ替えの順序は固定されています。
- Traversable世界は上位から下に入れ替わります。
- Applicative世界は下位から上に入れ替わります。
traverseの実装がすでにある場合、sequenceはそこから簡単に導出できることに注意してください。
実際、sequenceをtraverseにid関数を組み込んだものと考えることができます。
sequenceのアプリカティブバージョンとモナディックバージョン
Section titled “sequenceのアプリカティブバージョンとモナディックバージョン”traverseと同様に、sequenceにもアプリカティブバージョンとモナディックバージョンがあり得ます。
- アプリカティブなものには
sequenceA - モナディックなもの(または単に
sequence)にはsequenceM
Result用のsequence実装を実装してテストしてみましょう。
module List =
/// "list<Result>"を"Result<list>"に変換し /// applyを使用して結果を収集します /// Result<'a> list -> Result<'a list> let sequenceResultA x = traverseResultA id x
/// "list<Result>"を"Result<list>"に変換し /// bindを使用して結果を収集します /// Result<'a> list -> Result<'a list> let sequenceResultM x = traverseResultM id x簡単すぎましたね!では、テストしてみましょう。まずはアプリカティブバージョンから。
let goodSequenceA = ["1"; "2"; "3"] |> List.map parseInt |> List.sequenceResultA// Success [1; 2; 3]
let badSequenceA = ["1"; "x"; "y"] |> List.map parseInt |> List.sequenceResultA// Failure ["x is not an int"; "y is not an int"]次はモナディックバージョンです。
let goodSequenceM = ["1"; "2"; "3"] |> List.map parseInt |> List.sequenceResultM// Success [1; 2; 3]
let badSequenceM = ["1"; "x"; "y"] |> List.map parseInt |> List.sequenceResultM// Failure ["x is not an int"]以前と同様に、Result<List>が返されます。また、以前と同様に、モナディックバージョンは最初のエラーで停止し、アプリカティブバージョンはすべてのエラーを蓄積します。
アドホックな実装のレシピとしての「シーケンス」
Section titled “アドホックな実装のレシピとしての「シーケンス」”先ほど説明したように、Applicativeのような型クラスがサポートされている言語では、traverseとsequenceの実装は1回で済みます。
F#のような言語は高カインド型をサポートしていないので、走査したい型ごとに実装を作成する必要があります。
しかし、F#のような言語において、traverseとsequenceの概念は関係ない、抽象的すぎて役に立たない、ということでしょうか?そうは思いません。
これらをライブラリ関数として考えるのではなく、レシピ 、 つまり、特定の問題を解決するときに機械的に従うべき指示集として考えるのが有用だと思います。
多くの場合、問題はコンテキストに固有であり、ライブラリ関数を作成する必要はありません。必要に応じてヘルパー関数を作成すればいいからです。
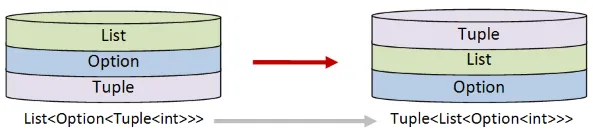
例を挙げて説明しましょう。タプルを含むオプションのリストが与えられたとします。このようなものです。
let tuples = [Some (1,2); Some (3,4); None; Some (7,8);]// List<Option<Tuple<int>>>このデータはList<Option<Tuple<int>>>の形式です。そして、何らかの理由で、これを各リストがオプションを含むタプルに変換する必要があるとします。
次のようなものです。
let desiredOutput = [Some 1; Some 3; None; Some 7],[Some 2; Some 4; None; Some 8]// Tuple<List<Option<int>>>望ましい結果はTuple<List<Option<int>>>の形式です。
では、この変換を行う関数をどう書くか、考えてみてください。急いで!
もちろん、何らかの解決策は思いつくでしょう。ただし、それを正しく行うには少し考えとテストが必要かもしれません。
一方で、この作業が単に世界のスタックを別のスタックに変換することだと認識すれば、ほとんど考えずに機械的に関数を作成できます。
解決策の設計
Section titled “解決策の設計”解決策を設計するには、どの世界が上に移動し、どの世界が下に移動するかに注意を払う必要があります。
- タプルの世界は最終的に一番上にある必要があるので、「上に」入れ替える必要があります。これは、「アプリカティブ」の役割を果たすことを意味します。
- オプションとリストの世界は「下に」入れ替える必要があります。これは、両方が「走査可能」の役割を果たすことを意味します。
この変換を行うために、2つのヘルパー関数が必要になります。
optionSequenceTupleはオプションを下に移動し、タプルを上に移動します。
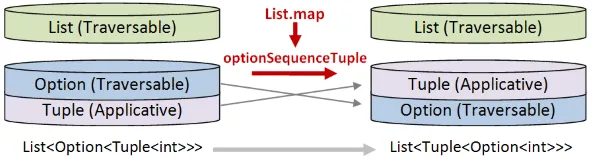
listSequenceTupleはリストを下に移動し、タプルを上に移動します。
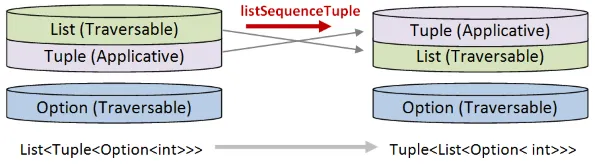
これらのヘルパー関数をライブラリに入れる必要はありますか? いいえ。 また必要になる可能性は低く、たまに必要になっても、依存関係を避けるためにゼロから書く方が良いでしょう。
一方で、前に実装したList.sequenceResult関数を考えてみましょう。この関数はList<Result<a>>をResult<List<a>>に変換します。
これは頻繁に使用するので、ライブラリ化する価値があります。
解決策の実装
Section titled “解決策の実装”解決策の構造が分かれば、機械的にコーディングを進められます。
まず、タプルがアプリカティブの役割を果たすように、applyとreturn関数を定義します。
let tupleReturn x = (x, x)let tupleApply (f,g) (x,y) = (f x, g y)次に、以前と全く同じ右畳み込みのテンプレートを使用して、Listを走査可能、タプルをアプリカティブとしてlistSequenceTupleを定義します。
let listSequenceTuple list = // アプリカティブ関数を定義 let (<*>) = tupleApply let retn = tupleReturn
// "cons"関数を定義 let cons head tail = head :: tail
// リストを右から畳み込む let initState = retn [] let folder head tail = retn cons <*> head <*> tail
List.foldBack folder list initStateここでは特に考える必要はありません。単にテンプレートに従うだけです。
すぐにテストしてみましょう。
[ (1,2); (3,4)] |> listSequenceTuple// 結果 => ([1; 3], [2; 4])そして、予想通り2つのリストを含むタプルが得られます。
同様に、同じ右畳み込みのテンプレートを再び使用してoptionSequenceTupleを定義します。
今回はOptionが走査可能で、タプルは依然としてアプリカティブです。
let optionSequenceTuple opt = // アプリカティブ関数を定義 let (<*>) = tupleApply let retn = tupleReturn
// オプションを右から畳み込む let initState = retn None let folder x _ = (retn Some) <*> x
Option.foldBack folder opt initStateこれもテストしてみましょう。
Some (1,2) |> optionSequenceTuple// 結果 => (Some 1, Some 2)そして、予想通り2つのオプションを含むタプルが得られます。
最後に、すべての部品を組み合わせます。ここでも特に考える必要はありません。
let convert input = input
// List<Option<Tuple<int>>>からList<Tuple<Option<int>>>へ |> List.map optionSequenceTuple
// List<Tuple<Option<int>>>からTuple<List<Option<int>>>へ |> listSequenceTupleそして、使ってみれば、期待通りのものが得られます。
let output = convert tuples// ( [Some 1; Some 3; None; Some 7], [Some 2; Some 4; None; Some 8] )
output = desiredOutput |> printfn "出力は正しいですか? %b"// 出力は正しいですか? true確かに、この解決策は、再利用可能な関数を1つ用意するよりも手間がかかりますが、機械的なので、コーディングにはほんの数分しかかかりません。 そして、自分で解決策を考え出すよりもはるかに簡単です。
もっと知りたいですか?実際の問題でsequenceを使う例については、この投稿を参照してください。
読みやすさ vs パフォーマンス
Section titled “読みやすさ vs パフォーマンス”この投稿の冒頭で、私たち関数型プログラマーの傾向として、まずmapを適用し、その後で質問する傾向があると述べました。
つまり、parseIntのようなResultを生成する関数があれば、まず結果を収集し、その後でそれらをどう扱うかを考えるでしょう。
そのため、コードは次のようになります。
["1"; "2"; "3"]|> List.map parseInt|> List.sequenceResultMしかし、これはリストを2回通過することになります。前述のように、traverseを使えばmapとsequenceを1ステップで組み合わせ、
リストを1回だけ走査すれば済みます。
["1"; "2"; "3"]|> List.traverseResultM parseInttraverseがより簡潔でおそらくより効率的であるなら、なぜsequenceを使うのでしょうか?
時には特定の構造が与えられて選択の余地がない場合もありますが、他の状況では、2ステップのmap-sequenceアプローチの方が理解しやすいため、私は前者のアプローチを選ぶことがあります。
「マップ」してから「入れ替える」という心的モデルは、ほとんどの人にとって1ステップの走査よりも把握しやすいようです。
言い換えれば、パフォーマンスへの影響が証明されない限り、読みやすさを優先することをお勧めします。多くの人がまだ関数型プログラミングを学んでいる段階です。 過度に難解な表現は理解の妨げになるというのが私の経験です。
ねえ、filterはどこ?
Section titled “ねえ、filterはどこ?”mapやsequenceなどの関数がリストを他の型に変換するのを見てきましたが、フィルタリングについてはどうでしょうか?これらの手法を使って要素をフィルタリングすることはできるのでしょうか?
答えは……できません! map、traverse、sequenceはすべて「構造を保持」します。
10個の要素を持つリストから始めると、結果も10個の要素を持つリストになります。ただし、スタックの位置が変わっているだけです。
あるいは、3つの枝を持つ木から始めると、結果も3つの枝を持つ木になります。
上のタプルの例では、元のリストに4つの要素がありましたが、変換後も、タプル内の2つの新しいリストにそれぞれ4つの要素があります。
型の構造を変更する必要がある場合は、foldのようなものを使用する必要があります。foldを使えば古い構造から新しい構造を構築できます。
つまり、foldを使って一部の要素が欠落した新しいリストを作成できます(それが、フィルタリングです)。
foldの様々な使用法は独自のシリーズに値するので、フィルタリングの議論は別の機会に取っておきます。
この投稿では、高次の値のリストを扱う方法としてtraverseとsequenceについて学びました。
次の投稿では、これまで議論してきたすべてのテクニックを使用する実践的な例を詳しく見ていきます。