依存関係の解釈
このシリーズでは、依存関係の注入の6つの異なるアプローチについて紹介しています。
- 第1回 では、「依存関係の保持」(コード内に直接埋め込む)と「依存関係の排除」(I/Oを実装の端に押し出す)について解説しました。
- 第2回 では、通常の関数引数を用いて依存関係を注入する方法を見てきました。
- 第3回 では、古典的なオブジェクト指向スタイルの依存関係の注入と、それに対応する関数型の手法である Reader モナドを紹介しました。
- 今回は、「インタープリターパターン」を用いることで、依存関係そのものを回避する方法を見ていきます。
- 次回 では、これまでに取り上げたすべての手法を再確認し、新たな例に適用していきます。
今回の記事の例は、前回までの投稿に登場した例をもとにしているため、そちらを先に読んでいただくことをおすすめします。
依存関係の解釈
Section titled “依存関係の解釈”「依存関係の排除」 アプローチでは、選択肢(choice 型など)を表すデータ構造を返し、最終段でその選択肢に基づいて I/O を実行する手法を紹介しました。これにより、コアのコードは純粋なままとなり、I/O はすべて端に押し出されました。
この考え方をさらに発展させ、すべての I/O をこの方法で扱うことができます。つまり、I/O を直接実行するのではなく、後で実行される I/O 処理の指示を表すデータ構造を返すようにします。
最初の試みとして、次のように I/O 命令のリストを返してみましょう。
type Instruction = | ReadLn | WriteLn of string
let readFromConsole() = let cmd1 = WriteLn "1つ目の値を入力してください" let cmd2 = ReadLn let cmd3 = WriteLn "2つ目の値を入力してください" let cmd4 = ReadLn
// I/O にやってほしい命令をすべて返す [cmd1; cmd2; cmd3; cmd4]そして、これらの命令を次のように解釈(実行)します。
let interpretInstruction instruction = match instruction with | ReadLn -> Console.ReadLine() | WriteLn str -> printfn "%s" strしかし、この方法には多くの問題があります。まず、interpretInstruction はコンパイルすら通りません。これは match 式の各分岐が異なる型を返すためです。
もっと深刻な問題として、この構造ではインタープリターの出力をコードの途中で利用することができません。たとえば、最初の ReadLn の結果を使って、2つ目の WriteLn の出力内容を変えたいとします。しかし、上記の設計ではそれが不可能です。
私たちが求めているのは、以下の図のようなアプローチです。つまり、各命令の出力が次の命令に渡されるようにしたいのです。
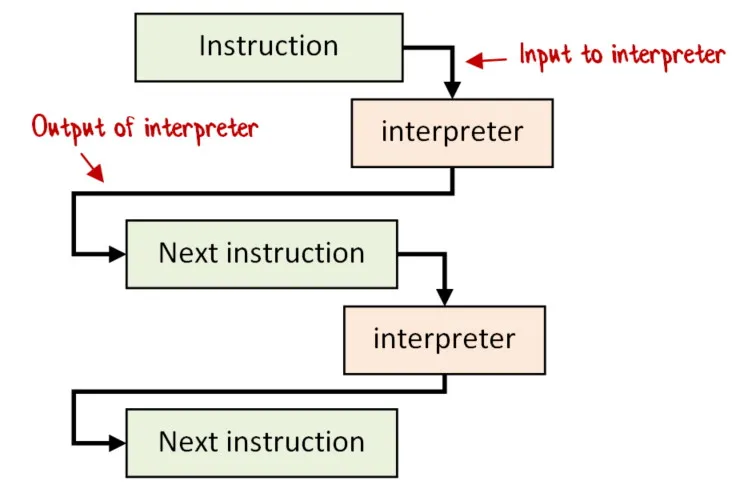
実はこれを実現することができます。コツは、命令を作成する際に、その命令の「実行後」に呼び出す関数(next 関数)も一緒に渡すことです。 インタープリターが命令を実行した後、その実行結果を next 関数に渡し、その関数が次の命令(Program)を返すという仕組みです。
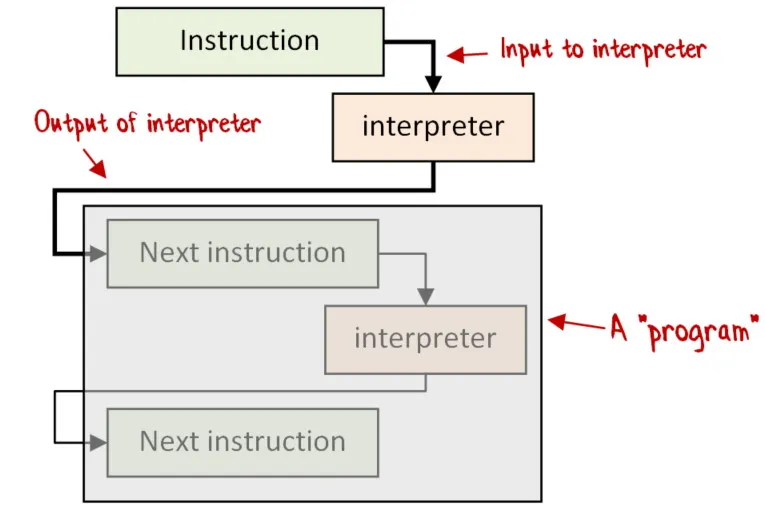
この一連の命令を「Program(プログラム)」と呼ぶことにします。Program は、純粋なコードと、後で解釈される命令が混在したものです。
そして、各命令について、インタープリターに渡すのは interpreterInput * (interpreterOutput -> Program) のペアになります。
具体的な例として ReadLn を見てみましょう。通常の ReadLn 関数は unit -> string というシグネチャを持ちます。この新しいアプローチでは、インタープリターに unit を渡し、その結果として string を得たい、ということになります。しかし実際には、その string を私たちが直接受け取るのではなく、インタープリターが next 関数に渡します。この next 関数は string -> Program というシグネチャを持ち、残りの処理を表します。
同様に、通常の WriteLn は string -> unit という型ですが、インタープリターアプローチでは string * (unit -> Program) のペアを渡すことになります。すなわち、文字列をインプットとして与え、出力として unit を next 関数に渡し、その関数が次の Program を返します。
以下のコードで、これを実装していきます。
まずは命令のセットを定義します。ここでは先ほどの規則に従って、命令全体の集合を Program と呼ぶことにします。
type Program<'a> = | ReadLn of unit * next:(string -> Program<'a>) | WriteLn of string * next:(unit -> Program<'a>) | Stop of 'aこの Program には、3種類の命令が含まれます。
-
ReadLnは、インタープリターへの入力は特になく(unit)、処理としては何らかの入力(例えば文字列)を読み込みます。そして、読み込んだ文字列をnext関数に渡します。この関数はstring -> Program<'a>という型で、次に実行すべきプログラムを返します。 -
WriteLnは、インタープリターへの入力として文字列を受け取り、それをどこかに出力します。その後、unitを引数に取るnext関数(unit -> Program<'a>)を呼び出し、次のプログラムを取得します。 -
Stopは、Programの終了を意味する命令です。next関数は持たず、インタープリターはこの命令を見た時点で再帰を終了し、関連付けられた値を返します。この値の型は任意であるため、Program全体も汎用型Program<'a>になっています。
この命令セットを使うコードは、次のようになります。
let readFromConsole = WriteLn ("1つ目の値を入力してください" , fun () -> ReadLn ( () , fun str1 -> WriteLn ("2つ目の値を入力してください", fun () -> ReadLn ( () , fun str2 -> Stop (str1, str2) // これ以上の next はない ))))ご覧の通り、各命令の後には次の命令を構成する関数が続いています。そして最後の Stop に到達すると、2つの文字列をタプルで返して終了します。
ここで重要なのは、readFromConsole は「関数」ではなく、「データ構造」だということです! この値は、WriteLn の中に ReadLn があり、さらにその中に WriteLn、その中にまた ReadLn、最終的に Stop というように、命令がネストされたデータ構造になっています。中に関数が含まれてはいますが、実行はされていません。
このようにして構築したデータ構造を「実行」するためには、インタープリターが必要になります。これまでの説明を理解していれば、この実装は難なく追えるはずです。 ReadLn や WriteLn の場合は再帰的に処理が続きますが、Stop に到達すると再帰をやめ、指定された値をそのまま返します。
let rec interpret program = match program with | ReadLn ((), next) -> // 1. "ReadLn" 命令を解釈して実際に I/O を行う let str = Console.ReadLine() // 2. 解釈結果を next 関数に渡して次のプログラムを取得 let nextProgram = next str // 3. 次のプログラムを再帰的に解釈 interpret nextProgram | WriteLn (str,next) -> printfn "%s" str let nextProgram = next() interpret nextProgram | Stop value -> // 最終的な結果を返す value試しに以下のように実行してみましょう。
interpret readFromConsoleうまく動きます!この記事の末尾にある gist で、このコードを試すこともできます。
コンピュテーション式を使って記述を簡単にする
Section titled “コンピュテーション式を使って記述を簡単にする”上記の readFromConsole のコードは、正直なところ記述しづらく、読みづらいですよね。もっと簡単に、分かりやすく書けるようにしたいところです。
実はこのような「逐次的な継続」(fun ... -> ... の連続)は、まさに コンピュテーション式 が解決を目的としている問題です!
それでは、この命令に対してコンピュテーション式を定義してみましょう。
まず、bind 関数を実装します。これは次の規則に基づいて機械的に作成できます:
Stopの場合は、戻り値に対して関数fを適用する。- その他の命令の場合は、
next関数をnext >> bind fに置き換える。
module Program = let rec bind f program = match program with | ReadLn ((),next) -> ReadLn ((),next >> bind f) | WriteLn (str,next) -> WriteLn (str, next >> bind f) | Stop x -> f xbind は再帰的に使われるため、let rec で定義する必要があります。
この bind 関数ができれば、コンピュテーション式ビルダーの定義が可能になります。
Bindメソッドは先ほどのbindを使用します。ReturnやZeroはStopを使って値を返します。
type ProgramBuilder() = member __.Return(x) = Stop x member __.Bind(x,f) = Program.bind f x member __.Zero() = Stop ()
// ビルダーのインスタンスを作成let program = ProgramBuilder()コンピュテーション式の中で使うヘルパー関数も定義しておくと便利です。これらの関数は処理を「行う」わけではなく、単にデータ構造を生成するだけです。
// コンピュテーション式内で使うヘルパーlet writeLn str = WriteLn (str,Stop)let readLn() = ReadLn ((),Stop)これで、program コンピュテーション式とヘルパー関数を使って、より見やすく readFromConsole を再定義できます。
let readFromConsole = program { do! writeLn "1つ目の値を入力してください" let! str1 = readLn() do! writeLn "2つ目の値を入力してください" let! str2 = readLn() return (str1,str2)}驚くべきことに、このコードは最初に紹介した「依存関係の保持」アプローチのコードとほとんど同じ見た目になります。依存関係を外部から渡すことなく、とてもすっきりと書けています。 もちろん、この実装の背後にはかなりの複雑さがありますし、「依存関係の保持」アプローチとは異なり、まだインタープリターを書く必要があります。
例に合わせた命令とインタープリターの設計
Section titled “例に合わせた命令とインタープリターの設計”それでは、これまでのシリーズで使ってきた例に、このインタープリターのアプローチを適用してみましょう。
まずは、プログラム中で使う命令を定義する必要があります。すべての命令を1つの Program 型に詰め込むのではなく、小さな構成要素から組み立てられるように設計してみましょう。これは、より複雑なシステムを構築する際に必要となる考え方です。
ここでは、コンソール用の命令とロガー用の命令の2種類を、それぞれ個別に定義します。
type ConsoleInstruction<'a> = | ReadLn of unit * next:(string -> 'a) | WriteLn of string * next:(unit -> 'a)
type LoggerInstruction<'a> = | LogDebug of string * next:(unit -> 'a) | LogInfo of string * next:(unit -> 'a)続いて、これら2つの命令を使って Program 型を定義します。Stop も、以前と同様に必要です。
type Program<'a> = | ConsoleInstruction of ConsoleInstruction<Program<'a>> | LoggerInstruction of LoggerInstruction<Program<'a>> | Stop of 'aさらに命令を追加したくなったら、新しい選択肢を加えるだけで済みます。
※注意:すべての選択肢を1つの高階型にまとめられるとよいのですが、F# で扱いやすい形はこの後で紹介します。
次に、プログラム用の bind 関数を実装します。ただし、各命令に対して bind を実装する必要はありません。命令ごとに map 関数さえあれば十分です。bind 関数が必要なのは、Program 全体に対してだけです。
以下は、それぞれの命令に対する map 関数です。
module ConsoleInstruction = let rec map f program = match program with | ReadLn ((),next) -> ReadLn ((),next >> f) | WriteLn (str,next) -> WriteLn (str, next >> f)
module LoggerInstruction = let rec map f program = match program with | LogDebug (str,next) -> LogDebug (str,next >> f) | LogInfo (str,next) -> LogInfo (str,next >> f)そして、Program に対する bind 関数は次のようになります。
module Program = let rec bind f program = match program with | ConsoleInstruction inst -> inst |> ConsoleInstruction.map (bind f) |> ConsoleInstruction | LoggerInstruction inst -> inst |> LoggerInstruction.map (bind f) |> LoggerInstruction | Stop x -> f xコンピュテーション式のビルダーに関しては、以前と同じ内容で問題ありません。
type ProgramBuilder() = member __.Return(x) = Stop x member __.Bind(x,f) = Program.bind f x member __.Zero() = Stop ()
// ビルダーインスタンスを作成let program = ProgramBuilder()最後に、インタープリターを実装します。基本的には先ほどと同じ構造ですが、今回は2つの命令セットに対応するサブインタープリターが含まれます。
let rec interpret program =
let interpretConsole inst = match inst with | ReadLn ((), next) -> let str = Console.ReadLine() interpret (next str) | WriteLn (str,next) -> printfn "%s" str interpret (next())
let interpretLogger inst = match inst with | LogDebug (str, next) -> printfn "DEBUG %s" str interpret (next()) | LogInfo (str, next) -> printfn "INFO %s" str interpret (next())
match program with | ConsoleInstruction inst -> interpretConsole inst | LoggerInstruction inst -> interpretLogger inst | Stop value -> valueパイプラインの構築
Section titled “パイプラインの構築”前回の記事 の Reader アプローチでは、ミニアプリケーションを次の3つの構成要素に分割しました:
readFromConsolecompareTwoStringswriteToConsole
インタープリターのアプローチでも、同じ分割方法を再利用できます。
まずは、Program を構成する命令を簡単に記述するためのヘルパー関数を定義します。
let writeLn str = ConsoleInstruction (WriteLn (str,Stop))let readLn() = ConsoleInstruction (ReadLn ((),Stop))let logDebug str = LoggerInstruction (LogDebug (str,Stop))let logInfo str = LoggerInstruction (LogInfo (str,Stop))それでは、ミニアプリケーションの3つの構成要素を作っていきましょう。
let readFromConsole = program { do! writeLn "1つ目の値を入力してください" let! str1 = readLn() do! writeLn "2つ目の値を入力してください" let! str2 = readLn() return (str1,str2)}続いて、
let compareTwoStrings str1 str2 = program { do! logDebug "compareTwoStrings: 開始"
let result = if str1 > str2 then Bigger else if str1 < str2 then Smaller else Equal
do! logInfo (sprintf "compareTwoStrings: 結果=%A" result) do! logDebug "compareTwoStrings: 終了" return result}そして、
let writeToConsole (result:ComparisonResult) = program { match result with | Bigger -> do! writeLn "1つ目の値の方が大きいです" | Smaller -> do! writeLn "1つ目の値の方が小さいです" | Equal -> do! writeLn "2つの値は同じです"}以上をすべて組み合わせると、最終的なプログラムは以下のようになります:
let myProgram = program { let! str1, str2 = readFromConsole let! result = compareTwoStrings str1 str2 do! writeToConsole result}このプログラムを「実行」するには、単にインタープリターに渡すだけです:
interpret myProgram複数の命令セットを扱うモジュール化された方法
Section titled “複数の命令セットを扱うモジュール化された方法”前述の方法には欠点があります。それは、新しい命令セットを追加するたびに、メインの Program 型を変更しなければならないという点です。これは保守性に乏しく、モジュール性にも欠けます。
そこで、代替となるアプローチを見ていきましょう。
Haskell や型クラス(特にファンクター)をサポートする他の言語では、これを「Free モナド」という形で実現できます。F# は Haskell ではありませんが、代わりにインターフェースを使って似たようなことができます。
まずは、命令が実装すべきインターフェースを定義します。ここでは Map メソッドを持つ IInstruction<'a> を定義します。
type IInstruction<'a> = abstract member Map : ('a -> 'b) -> IInstruction<'b>次に、Program をこのインターフェースに基づいて定義します。
type Program<'a> = | Instruction of IInstruction<Program<'a>> | Stop of 'aそして、命令に紐づく Map メソッドを使って bind を実装します。
module Program = let rec bind f program = match program with | Instruction inst -> inst.Map (bind f) |> Instruction | Stop x -> f xコンピュテーション式ビルダーは以前と同様に定義できます。
ここまでのコードは、特定の命令セットに一切依存しておらず、完全に汎用的で再利用可能な実装になっています。
この仕組みを使って実際のワークフローを定義するには、まず命令とその Map メソッドを定義します。これらの命令は互いに独立しており、それぞれがモジュール化されています。
type ConsoleInstruction<'a> = | ReadLn of unit * next:(string -> 'a) | WriteLn of string * next:(unit -> 'a) interface IInstruction<'a> with member this.Map f = match this with | ReadLn ((), next) -> ReadLn ((), next >> f) | WriteLn (str, next) -> WriteLn (str, next >> f) :> IInstruction<'b>
type LoggerInstruction<'a> = | LogDebug of string * next:(unit -> 'a) | LogInfo of string * next:(unit -> 'a) interface IInstruction<'a> with member this.Map f = match this with | LogDebug (str, next) -> LogDebug (str, next >> f) | LogInfo (str, next) -> LogInfo (str, next >> f) :> IInstruction<'b>この新しい実装で異なるのは、Map メソッドが結果を IInstruction にキャストして返す必要がある点だけです。
コンピュテーション式内で使うヘルパー関数はほとんど変わりません。ただし、より汎用的な Instruction ケースを使うようになります。
let writeLn str = Instruction (WriteLn (str, Stop))let readLn() = Instruction (ReadLn ((), Stop))let logDebug str = Instruction (LogDebug (str, Stop))let logInfo str = Instruction (LogInfo (str, Stop))このように、新しい汎用的な Program 型を使っていても、ヘルパー関数が内部の差異を隠してくれるため、アプリケーション本体のコードは変更せずに済みます。たとえば、readFromConsole は以下のように以前と全く同じ見た目になります。
let readFromConsole = program { do! writeLn "1つ目の値を入力してください" let! str1 = readLn() do! writeLn "2つ目の値を入力してください" let! str2 = readLn() return (str1, str2)}モジュール化されたインタープリターの構築
Section titled “モジュール化されたインタープリターの構築”インタープリターもモジュール化して構築したいところです。つまり、特定の命令セットに対応するインタープリターは、トップレベルのインタープリターを意識することなく設計できるようにします。そのために、interpret 関数自身を引数として渡すようにします。
// ConsoleInstruction 用のモジュール化されたインタープリターlet interpretConsole interpret inst = match inst with | ReadLn ((), next) -> let str = Console.ReadLine() interpret (next str) | WriteLn (str, next) -> printfn "%s" str interpret (next())
// LoggerInstruction 用のモジュール化されたインタープリターlet interpretLogger interpret inst = match inst with | LogDebug (str, next) -> printfn "DEBUG %s" str interpret (next()) | LogInfo (str, next) -> printfn "INFO %s" str interpret (next())最後に、トップレベルのインタープリターを定義します。ここでは、固定の命令セットを列挙するのではなく、命令の 型 に基づいて判別します。型安全性にはやや劣りますが、未処理の命令があればすぐにエラーになります。
let rec interpret program = match program with | Instruction inst -> match inst with | :? ConsoleInstruction<Program<_>> as i -> interpretConsole interpret i | :? LoggerInstruction<Program<_>> as i -> interpretLogger interpret i | _ -> failwithf "未知の命令タイプです: %O" (inst.GetType()) | Stop value -> valueこのアプローチの利点は、モジュール性が非常に高いという点です。異なる命令セットを使って構築されたサブコンポーネントを、それぞれ独立して記述し、後から組み合わせることができます。変更が必要なのは、特定のワークフローに対するトップレベルのインタープリターだけであり、その中でも必要な部分のサブインタープリターを順次組み合わせるだけで済みます。
インタープリターアプローチの他の実例としては、本シリーズの最終回 をご覧ください。
ここで紹介したインタープリター方式は、Haskell や FP スタイルの Scala で用いられる「Free モナド」アプローチと密接な関係があります。Free モナドはさらに抽象度が高く、「Program」型の各ケースにも数学的な名称(Free や Pure)が使われます。実際に使う機会は少ないかもしれませんが、理解しておく価値はあるでしょう。
Mark Seemann 氏による F# における Free モナドの素晴らしい解説記事もあります。たとえば、実装レシピ や Free モナドの合成方法 などです。
実践例としては、Chris Myers 氏による Scala を使った 講演動画 があります。逆に、注意点を述べたものとしては Kelley Robinson 氏による Free Monads Aren’t Free という講演も参考になります。
インタープリターの利点と欠点
Section titled “インタープリターの利点と欠点”ご覧の通り、インタープリターを用いた場合、依存関係が隠蔽された非常にクリーンなコードになります。Async などの扱いにくい I/O を気にする必要がなくなります(正確には、インタープリター側に押し出すことができます)。
また、異なるインフラに対応するために、インタープリターを差し替えるのも容易です。たとえば、ロガーの処理を Serilog に変える、コンソール出力をファイルやソケットに切り替えるといったことが簡単にできます。「グローバルな値」(ロガーなど)も、インタープリター側で集中管理でき、プログラム本体の論理には影響しません。
しかし、当然ながらトレードオフもあります。
まず、準備作業が非常に多いことです。ワークフローで必要となるあらゆる I/O 処理について、命令の定義とインタープリターでの解釈処理を用意しなければなりません。操作の数が増えすぎると、すぐに手に負えなくなります。その点で、システムを小さな独立したワークフローの集合として設計する ことが有効です。
次に、こうしたアプローチに不慣れな人にとっては、非常に理解しづらいという点があります。「依存関係の排除」や「依存関係のパラメータ化」といった手法は特別な知識を必要としませんが、Reader やインタープリターのような手法には、ある程度の理解が求められます。また、デバッガでステップ実行しようとすると、継続が深くネストしているため非常に追いづらくなります。
さらに、コンピュテーション式のデメリットとして、複数のコンピュテーション式をうまく組み合わせるのが難しいという点があります。前回も述べたように、Reader コンピュテーション式と Result コンピュテーション式、Async コンピュテーション式を組み合わせるのは困難です。インタープリター方式ではこの問題はある程度緩和され、Async を直接扱う必要はなくなる場合も多いです。しかし、それでも問題が完全になくなるわけではありません。
最後に、パフォーマンスの問題があります。命令の数が何千にも及ぶような大規模なプログラムになると、非常に深いネストのあるデータ構造が生成されます。 解釈に時間がかかるだけでなく、メモリ消費やガーベジコレクションの回数が増え、最悪の場合はスタックオーバーフローすら発生します。対策としては、「トランポリン」 などの手法がありますが、コードはさらに複雑になります。
まとめると、この手法を採用するのは、以下の条件をすべて満たす場合に限るのが良いでしょう。 (a) I/O と純粋なコードを完全に分離したいと考えている。 (b) チームの全員がこの技術に習熟している。 (c) パフォーマンスの問題が起きた場合に対処できるスキルと知識を持っている。
次回の記事 では、ここまでに紹介したすべての技術を振り返り、新たな例に適用していきます。
この投稿のソースコードは この gist で公開されています。