コア関数の実際的な使い方
この投稿は、シリーズの3番目です。
前の2つの投稿では、ジェネリックなデータ型を扱うためのコア関数について説明しました。map、apply、bindなどです。
今回の投稿では、これらの関数を実際にどう使うか、そして「アプリカティブ」スタイルと「モナディック」スタイルの違いについて説明します。
シリーズの内容
Section titled “シリーズの内容”このシリーズで触れる様々な関数へのショートカットリストです。
- パート1:高次の世界への持ち上げ
- パート2:世界をまたぐ関数の合成方法
- パート3:コア関数の実際的な使い方
- パート4:リストと高次の値の混合
- パート5:すべてのテクニックを使用する実世界の例
- パート6:独自の高次の世界を設計する
- パート7:まとめ
パート3:コア関数の実際的な使い方
Section titled “パート3:コア関数の実際的な使い方”通常の値を高次の値に引き上げ、世界を超える関数を扱う基本的なツールを手に入れました。ここからは、これらを実際に使ってみましょう。
このセクションでは、これらの関数が実際にどのように使われるかを見ていきます。
独立したデータと依存したデータ
Section titled “独立したデータと依存したデータ”先ほど、applyとbindの使用には重要な違いがあると簡単に触れました。ここで詳しく見ていきましょう。
applyを使う場合、各パラメータ(E<a>、E<b>)は完全に独立しています。E<b>の値はE<a>に依存しません。
![]()
一方、bindを使う場合、E<b>の値はE<a>に依存します。
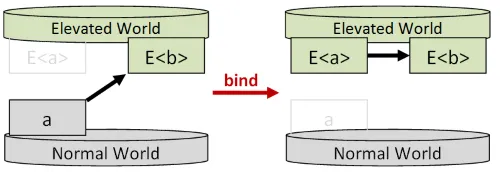
独立した値と依存した値を扱う違いにより、2つの異なるスタイルが生まれます。
- いわゆる「アプリカティブ」スタイルでは、
apply、lift、combineなどの関数を使います。高次の値はそれぞれ独立しています。 - いわゆる「モナディック」スタイルでは、
bindなどの関数を使って、前の値に依存する関数をつなげます。
実際にはどういう意味があるのでしょうか?両方のアプローチを選択できる例を見てみましょう。
3つのWebサイトからデータをダウンロードして組み合わせる必要があるとします。そして、GetURLというアクションがあり、これがオンデマンドでWebサイトからデータを取得するとします。
ここで選択肢があります。
- 全てのURLを並行してフェッチしたいですか?
その場合、
GetURLを独立したデータとして扱い、アプリカティブスタイルを使います。 - 各URLを一度に1つずつフェッチし、前のフェッチが失敗した場合は次のフェッチをスキップしたいですか?
その場合、
GetURLを依存したデータとして扱い、モナディックスタイルを使います。 この線形アプローチは上記の「アプリカティブ」版よりも全体的に遅くなりますが、不要なI/Oを避けることができます。 - 次のサイトのURLが前のサイトからダウンロードしたものに依存していますか?
この場合、各
GetURLが前の出力に依存するため、「モナディック」スタイルを使わざるを得ません。
見てわかるように、アプリカティブスタイルとモナディックスタイルの選択は明確ではありません。やりたいことによって変わります。
この例の実際の実装は、このシリーズの最終投稿で見ていきます。
ただし…
スタイルを選択したからといって、期待通りに実装されるとは限りません。
既に見たように、bindを使ってapplyを簡単に実装できます。つまり、コードで<*>を使っていても、実装はモナディックに進行している可能性があります。
上記の例では、実装がダウンロードを並行して実行する必要はありません。代わりに直列に実行することもできます。 アプリカティブスタイルを使うことで、依存関係を気にせず、並行してダウンロードできると言っているだけです。
静的構造と動的構造
Section titled “静的構造と動的構造”アプリカティブスタイルを使うと、全てのアクションを前もって定義することになります。いわば「静的」に定義するわけです。
ダウンロードの例では、アプリカティブスタイルでは、どのURLを訪れるかを前もって指定する必要があります。 前もって多くの情報がわかるため、並列化やその他の最適化を潜在的に行うことができます。
一方、モナディックスタイルでは、最初のアクションだけが前もってわかっています。 残りのアクションは、前のアクションの出力に基づいて動的に決まります。これはより柔軟ですが、全体像を前もって把握する能力も制限されます。
評価順序と依存関係
Section titled “評価順序と依存関係”時々、依存関係と評価順序が混同されることがあります。
確かに、ある値が別の値に依存する場合、最初の値は2番目の値の前に評価されなければなりません。 理論的には、値が完全に独立している(そして副作用がない)場合、どのような順序でも評価できます。
しかし、値が完全に独立していても、評価方法に暗黙の順序がある場合があります。
たとえば、GetURLのリストが並行して行われる場合でも、
URLは最初のものから順にリストされた順序でフェッチされ始める可能性が高いです。
そして、前回の投稿で実装したList.applyでは、[f; g] apply [x; y]の結果は[f x; g x; f y; g y]ではなく[f x; f y; g x; g y]になりました。
つまり、全てのfの値が最初に来て、次に全てのgの値が来ます。
一般的に、値が独立していても、左から右の順序で評価されるという慣例があります。
例:アプリカティブスタイルとモナディックスタイルを使用したバリデーション
Section titled “例:アプリカティブスタイルとモナディックスタイルを使用したバリデーション”アプリカティブスタイルとモナディックスタイルの両方がどのように使用できるかを見るために、バリデーションの例を見てみましょう。
CustomerId、EmailAddress、そしてこれら両方を含むレコードであるCustomerInfoからなる簡単なドメインがあるとします。
type CustomerId = CustomerId of inttype EmailAddress = EmailAddress of stringtype CustomerInfo = { id: CustomerId email: EmailAddress }そして、CustomerIdの作成にはバリデーションがあるとしましょう。たとえば、内部のintは正の数でなければならないなどです。
もちろん、EmailAddressの作成にもバリデーションがあります。たとえば、少なくとも「@」記号を含んでいなければならないなどです。
これをどのように実装しますか?
まず、バリデーションの成功/失敗を表す型を作ります。
type Result<'a> = | Success of 'a | Failure of string list注意すべき点は、Failureケースに文字列のリストを含めていることです。これは後で重要になります。
Resultを手に入れたので、2つのコンストラクタ/バリデーション関数を定義できます。
let createCustomerId id = if id > 0 then Success (CustomerId id) else Failure ["CustomerId must be positive"]// int -> Result<CustomerId>
let createEmailAddress str = if System.String.IsNullOrEmpty(str) then Failure ["Email must not be empty"] elif str.Contains("@") then Success (EmailAddress str) else Failure ["Email must contain @-sign"]// string -> Result<EmailAddress>createCustomerIdの型はint -> Result<CustomerId>で、createEmailAddressの型はstring -> Result<EmailAddress>です。
つまり、これらのバリデーション関数はどちらも世界をまたぐ関数で、通常の世界からResult<_>の世界に移動します。
Resultのコア関数の定義
Section titled “Resultのコア関数の定義”世界をまたぐ関数を扱っているので、applyやbindのような関数を使う必要があることがわかります。Result型に対してこれらを定義しましょう。
module Result =
let map f xResult = match xResult with | Success x -> Success (f x) | Failure errs -> Failure errs // シグネチャ:('a -> 'b) -> Result<'a> -> Result<'b>
// "return"はF#のキーワードなので、省略形を使います let retn x = Success x // シグネチャ:'a -> Result<'a>
let apply fResult xResult = match fResult,xResult with | Success f, Success x -> Success (f x) | Failure errs, Success x -> Failure errs | Success f, Failure errs -> Failure errs | Failure errs1, Failure errs2 -> // 両方のエラーリストを連結します Failure (List.concat [errs1; errs2]) // シグネチャ:Result<('a -> 'b)> -> Result<'a> -> Result<'b>
let bind f xResult = match xResult with | Success x -> f x | Failure errs -> Failure errs // シグネチャ:('a -> Result<'b>) -> Result<'a> -> Result<'b>シグネチャを確認すると、望んでいた通りになっています。
mapのシグネチャ:('a -> 'b) -> Result<'a> -> Result<'b>retnのシグネチャ:'a -> Result<'a>applyのシグネチャ:Result<('a -> 'b)> -> Result<'a> -> Result<'b>bindのシグネチャ:('a -> Result<'b>) -> Result<'a> -> Result<'b>
モジュール内でretn関数を定義しましたが、あまり使わないかもしれません。returnの概念は重要ですが、実際にはSuccessコンストラクタを直接使うでしょう。
Haskellのような型クラスを持つ言語では、returnがもっと使われます。
また、applyは両方のパラメータが失敗の場合、各側のエラーメッセージを連結することに注意してください。
これにより、エラーを捨てることなく全ての失敗を収集できます。Failureケースに単一の文字列ではなく文字列のリストを持たせた理由はこれです。
注:デモを簡単にするため、失敗ケースにstringを使っています。より洗練された設計では、可能な失敗を明示的にリストアップします。
詳細は関数型エラーハンドリングの講演を参照してください。
アプリカティブスタイルを使ったバリデーション
Section titled “アプリカティブスタイルを使ったバリデーション”Resultに関するドメインとツールセットを手に入れたので、アプリカティブスタイルを使ってCustomerInfoレコードを作成してみましょう。
バリデーションの出力は既にResultに高次化されているので、それらを扱うには何らかの「リフティング」アプローチが必要だとわかります。
まず、通常のCustomerIdと通常のEmailAddressを受け取り、通常の世界でCustomerInfoレコードを作成する関数を作ります。
let createCustomer customerId email = { id=customerId; email=email }// CustomerId -> EmailAddress -> CustomerInfoシグネチャはCustomerId -> EmailAddress -> CustomerInfoです。
ここで、前回の投稿で説明した<!>と<*>を使ったリフティング技法を使えます。
let (<!>) = Result.maplet (<*>) = Result.apply
// アプリカティブバージョンlet createCustomerResultA id email = let idResult = createCustomerId id let emailResult = createEmailAddress email createCustomer <!> idResult <*> emailResult// int -> string -> Result<CustomerInfo>このシグネチャを見ると、通常のintとstringから始めてResult<CustomerInfo>を返すことがわかります。
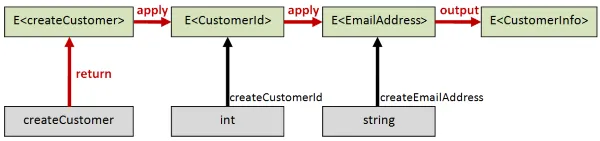
良いデータと悪いデータで試してみましょう。
let goodId = 1let badId = 0let goodEmail = "test@example.com"let badEmail = "example.com"
let goodCustomerA = createCustomerResultA goodId goodEmail// Result<CustomerInfo> =// Success {id = CustomerId 1; email = EmailAddress "test@example.com";}
let badCustomerA = createCustomerResultA badId badEmail// Result<CustomerInfo> =// Failure ["CustomerId must be positive"; "Email must contain @-sign"]goodCustomerAはSuccessで、正しいデータを含んでいます。一方、badCustomerAはFailureで、2つのバリデーションエラーメッセージを含んでいます。素晴らしい!
モナディックスタイルを使ったバリデーション
Section titled “モナディックスタイルを使ったバリデーション”次に、モナディックスタイルを使って別の実装を行いましょう。このバージョンでは、以下のようなロジックになります。
- まず、intを
CustomerIdに変換しようとします。 - それが成功したら、文字列を
EmailAddressに変換しようとします。 - それも成功したら、customerId と email から
CustomerInfoを作成します。
コードは以下の通りです。
let (>>=) x f = Result.bind f x
// モナディックバージョンlet createCustomerResultM id email = createCustomerId id >>= (fun customerId -> createEmailAddress email >>= (fun emailAddress -> let customer = createCustomer customerId emailAddress Success customer ))// int -> string -> Result<CustomerInfo>モナディックスタイルのcreateCustomerResultMのシグネチャは、アプリカティブスタイルのcreateCustomerResultAと全く同じです。しかし、内部で行っていることが異なります。
これは、得られる結果の違いに反映されます。
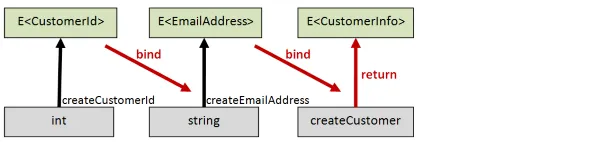
let goodCustomerM = createCustomerResultM goodId goodEmail// Result<CustomerInfo> =// Success {id = CustomerId 1; email = EmailAddress "test@example.com";}
let badCustomerM = createCustomerResultM badId badEmail// Result<CustomerInfo> =// Failure ["CustomerId must be positive"]適切な顧客の場合、最終結果は同じですが、適切でない顧客の場合、エラーが1つだけ返されます。最初のエラーです。
CustomerIdの作成が失敗した後、残りのバリデーションは短絡的に処理されました。
2つのスタイルの比較
Section titled “2つのスタイルの比較”この例は、アプリカティブスタイルとモナディックスタイルの違いをうまく示していると思います。
- アプリカティブの例では、全てのバリデーションを前もって行い、その後で結果を組み合わせました。 利点は、バリデーションエラーを1つも失わなかったことです。 欠点は、必要でない可能性のある作業を行ったことです。
- 一方、モナディックの例では、バリデーションを1つずつ、連鎖的に行いました。 利点は、エラーが発生するとすぐにチェーンの残りを短絡的に処理し、余分な作業を避けられたことです。 欠点は、最初のエラーしか得られなかったことです。
2つのスタイルの混合
Section titled “2つのスタイルの混合”アプリカティブスタイルとモナディックスタイルを混ぜて使うことも可能です。
たとえば、エラーを失わないようにアプリカティブスタイルを使ってCustomerInfoを構築し、
その後のプログラムで、バリデーションの後にデータベースの更新が続く場合は、
モナディックスタイルを使って、バリデーションが失敗した場合にデータベースの更新をスキップすることができます。
F#のコンピュテーション式の使用
Section titled “F#のコンピュテーション式の使用”最後に、これらのResult型用のコンピュテーション式を作成しましょう。
これを行うには、ReturnとBindというメンバーを持つクラスを定義し、そのクラスのインスタンスを作成するだけです。たとえばresultという名前にします。
module Result =
type ResultBuilder() = member this.Return x = retn x member this.Bind(x,f) = bind f x
let result = new ResultBuilder()これでcreateCustomerResultM関数を次のように書き直せます。
let createCustomerResultCE id email = result { let! customerId = createCustomerId id let! emailAddress = createEmailAddress email let customer = createCustomer customerId emailAddress return customer }このコンピュテーション式バージョンは、命令型言語を使用しているかのように見えます。
F#のコンピュテーション式は、HaskellのDo記法やScalaのfor内包表記と同様に、常にモナディックであることに注意してください。 これは一般的に問題ではありません。アプリカティブスタイルが必要な場合、言語サポートなしで非常に簡単に書けるからです。
一貫した世界への持ち上げ
Section titled “一貫した世界への持ち上げ”実践では、しばしば異なる種類の値と関数が混在しており、それらを組み合わせる必要があります。
これを行うコツは、全てを同じ型に変換することです。その後で簡単に組み合わせることができます。
値の一貫性を保つ
Section titled “値の一貫性を保つ”前回のバリデーション例を再び見てみましょう。ただし、レコードにnameという文字列型の追加プロパティがあるように変更します。
type CustomerId = CustomerId of inttype EmailAddress = EmailAddress of string
type CustomerInfo = { id: CustomerId name: string // 新規追加! email: EmailAddress }以前と同様に、通常の世界でCustomerInfoレコードを作成する関数を作成し、後でResultの世界に持ち上げます。
let createCustomer customerId name email = { id=customerId; name=name; email=email }// CustomerId -> String -> EmailAddress -> CustomerInfoこれで、追加パラメータを含む高次のcreateCustomerを更新する準備ができました。
let (<!>) = Result.maplet (<*>) = Result.apply
let createCustomerResultA id name email = let idResult = createCustomerId id let emailResult = createEmailAddress email createCustomer <!> idResult <*> name <*> emailResult// エラー ~~~~しかし、これはコンパイルできません!idResult <*> name <*> emailResultというパラメータの列の中で、1つだけ他と異なるものがあります。
問題は、idResultとemailResultは両方とも Result ですが、nameはまだ文字列のままだということです。
修正方法は、nameをreturnを使って Result の世界に持ち上げる(nameResultとする)ことです。Resultの場合、returnは単にSuccessです。
以下が修正版の関数で、これは機能します。
let createCustomerResultA id name email = let idResult = createCustomerId id let emailResult = createEmailAddress email let nameResult = Success name // name を Result に持ち上げる createCustomer <!> idResult <*> nameResult <*> emailResult関数の一貫性を保つ
Section titled “関数の一貫性を保つ”同じテクニックを関数にも適用できます。
たとえば、4つのステップからなる簡単な顧客更新ワークフローがあるとします。
- まず、入力を検証します。この出力は、先ほど作成した
Result型と同じ種類のものです。 この検証関数自体が、applyを使って他の小さな検証関数を組み合わせた結果である可能性があります。 - 次に、データを正規化します。たとえば、メールアドレスを小文字にしたり、空白を削除したりします。このステップではエラーは発生しません。
- 次に、既存のレコードをデータベースから取得します。たとえば、
CustomerIdに対応する顧客を取得します。このステップでもエラーが発生する可能性があります。 - 最後に、データベースを更新します。このステップは「行き止まり」関数です - 出力はありません。
エラー処理のために、成功トラックと失敗トラックの2つのトラックがあると考えるのが好きです。 このモデルでは、エラーを生成する関数は鉄道のポイント(分岐器)に似ています。

問題は、これらの関数をつなげられないことです。全て形が異なります。
解決策は、全ての関数を同じ形に変換することです。この場合、成功と失敗が異なるトラックにある2トラックモデルです。 これを2トラック世界と呼びましょう!
ツールセットを使った関数の変換
Section titled “ツールセットを使った関数の変換”各オリジナルの関数を2トラック世界に高次化する必要があります。そのためのツールがあることを私たちは知っています!
Canonicalize関数は単一トラック関数です。mapを使って2トラック関数に変換できます。
DbFetch関数は世界をまたぐ関数です。bindを使って完全な2トラック関数に変換できます。

DbUpdate関数はより複雑です。行き止まりの関数は好ましくないので、まずデータが流れ続ける関数に変換する必要があります。
この関数をteeと呼びましょう。teeの出力は1つのトラックが入力され1つのトラックが出力されるので、再びmapを使って2トラック関数に変換する必要があります。

これらの変換の後、新しいバージョンの関数を再構成できます。結果は次のようになります。

そしてもちろん、これらの関数を非常に簡単に組み合わせられるので、最終的に次のような1つの関数になります。 1つの入力と成功/失敗の出力を持ちます。
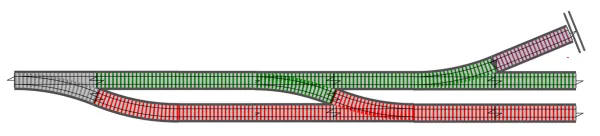
この組み合わされた関数は、a->Result<b>の形の別の世界をまたぐ関数であり、さらに大きな関数のコンポーネント部分として使用できます。
この「全てを同じ世界に高次化する」アプローチの詳細な例については、 関数型エラー処理と状態のスレッド処理に関する私の投稿を参照してください。
Kleisli世界
Section titled “Kleisli世界”一貫性の基礎として使用できる別の世界があります。これを「Kleisli」世界と呼びます。 もちろん、数学者のKleisli教授にちなんで名付けられました。
Kleisli世界では、全てが世界をまたぐ関数です!または、鉄道のアナロジーを使えば、全てがポイント(分岐器)です。
Kleisli世界では、世界をまたぐ関数を直接合成できます。
左から右への合成には>=>演算子を、右から左への合成には<=<演算子を使います。

先ほどと同じ例を使って、全ての関数をKleisli世界に持ち上げることができます。
ValidateとDbFetch関数は既に正しい形なので、変更する必要はありません。- 単一トラックの
Canonicalize関数は、出力を2トラック値に持ち上げるだけでスイッチに変換できます。これをtoSwitchと呼びましょう。
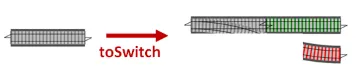
- Tee処理された
DbUpdate関数も、Tee処理の後にtoSwitchを行うだけでスイッチに変換できます。

全ての関数がKleisli世界に持ち上げられたら、Kleisli合成で組み合わせることができます。

Kleisli世界には2トラック世界にはない素晴らしい特性がありますが、私にとっては理解が難しいものです! そのため、このようなことには通常、2トラック世界を基礎として使用しています。
この投稿では、「アプリカティブ」スタイルと「モナディック」スタイルについて学び、その選択がどのアクションが実行されるか、どのような結果が返されるかに重要な影響を与える可能性があることを理解しました。
また、異なる種類の値と関数を一貫した世界に持ち上げて、簡単に扱えるようにする方法も見ました。
次の投稿では、高次の値のリストを扱うという一般的な問題について見ていきます。