プロジェクトにおけるモジュールの整理
コーディングに進む前に、F#プロジェクトの全体構造を見てみましょう。特に以下の2点に注目します。(a)どのコードをどのモジュールに配置するか、(b)プロジェクト内でモジュールをどう整理するか。
避けるべき方法
Section titled “避けるべき方法”F#初心者は、C#と同じようにクラスでコードを整理したくなるかもしれません。1ファイルに1クラス、アルファベット順に並べる、といった具合です。F#はC#と同じオブジェクト指向の機能をサポートしているのだから、C#コードと同じように整理できるはずだ、と考えるでしょう。
しかし、そのうちF#ではファイル(およびファイル内のコード)を依存順に並べる必要があることに気づきます。つまり、コンパイラがまだ認識していないコードへの前方参照はできません**。
この発見は一般的な不満と悪態につながります。F#はなんてバカなんだ!大規模なプロジェクトを書くのは不可能だ!
この記事では、このような問題を回避する簡単な方法を紹介します。
** andキーワードを使用して相互再帰を可能にする場合もありますが、推奨されません。
関数型アプローチによるレイヤードアーキテクチャ
Section titled “関数型アプローチによるレイヤードアーキテクチャ”コードを考える標準的な方法は、ドメイン層、プレゼンテーション層などの層(レイヤー)に分けることです。次の図のようになります。
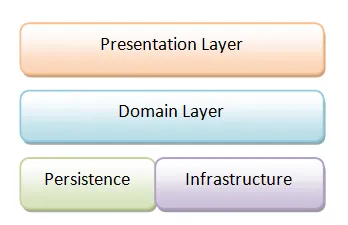
各層には、その層に関連するコードのみが含まれます。
しかし実際には、そう単純ではありません。各層間には依存関係があるからです。ドメイン層はインフラストラクチャに依存し、プレゼンテーション層はドメインに依存します。
最も重要なのは、ドメイン層が永続化層に依存しないことです。つまり、「永続化に関して無知」であるべきです。
そのため、レイヤーの図を次のように調整する必要があります(矢印は依存を表します)。
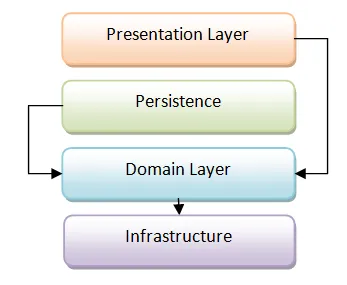
理想的には、この再編成をさらに細分化し、アプリケーションサービス、ドメインサービスなどを含む別の「サービス層」を設けます。最終的に、コアとなるドメインクラスは「純粋」で、ドメイン外の何にも依存しません。これは「ヘキサゴナルアーキテクチャ」や「オニオンアーキテクチャ」と呼ばれることがあります。ただし、この記事ではオブジェクト指向設計の微妙な点については触れません。今は、よりシンプルなモデルで考えていきましょう。
振る舞いと型の分離
Section titled “振る舞いと型の分離”「10個のデータ構造に対して10個の関数を持つよりも、1つのデータ構造に対して100個の関数を持つ方が良い」 — アラン・パーリス
関数型設計では、振る舞いをデータから分離することが非常に重要です。データ型はシンプルで「愚直」です。そして別個に、それらのデータ型に対して動作する多数の関数があります。
これはオブジェクト指向設計とは正反対です。オブジェクト指向では、振る舞いとデータを組み合わせることが意図されています。結局のところ、それがクラスの本質です。実際、真のオブジェクト指向設計では、振る舞い以外は何も持つべきではありません。データはプライベートで、メソッドを通じてのみアクセスできます。
事実、オブジェクト指向設計では、データ型の周りに十分な振る舞いがないことは悪いことと考えられ、「ドメインモデル貧血症」という名前さえついています。
一方、関数型設計では、透明性を持つ「愚直なデータ」が好まれます。通常、データをカプセル化せずに公開しても問題ありません。データは不変なので、誤った関数によって「破壊」されることはありません。そして、透明なデータに焦点を当てることで、より柔軟で汎用的なコードが可能になることがわかります。
まだ見ていない方は、Rich Hickeyの素晴らしい講演「The Value of Values」をお勧めします。このアプローチの利点が説明されています。
型の層と振る舞いの層
Section titled “型の層と振る舞いの層”では、これを先ほどのレイヤードアーキテクチャにどう適用すればよいでしょうか?
まず、各層を2つの明確な部分に分けます。
- データ型:その層で使用されるデータ構造。
- ロジック:その層で実装される関数。
これら2つの要素を分離すると、図は次のようになります。
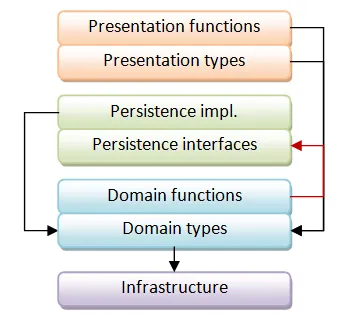
ただし、後方参照(赤い矢印で示す)が生じる可能性があります。たとえば、ドメイン層の関数がIRepositoryのような永続化関連の型に依存する場合があります。
オブジェクト指向設計では、これに対処するためにさらに層を追加(例:アプリケーションサービス)します。しかし関数型設計では、そうする必要はありません。永続化関連の型をレイヤーの別の場所、つまりドメイン関数の下に移動するだけです。次のようになります。
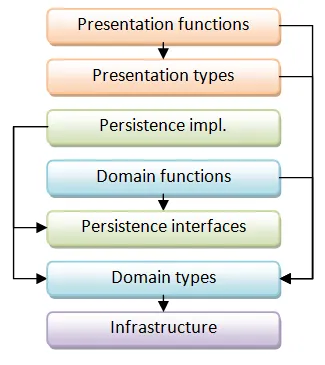
この設計では、レイヤー間の循環参照をすべて排除しました。すべての矢印が下向きになります。
そして、これは余分な層やオーバーヘッドを作ることなく実現できます。
最後に、このレイヤードアーキテクチャをF#ファイルに変換するには、上下を反転させます。
- プロジェクトの最初のファイルには、依存関係のないコードを含めます。これはレイヤー図の一番下の機能を表します。通常、インフラストラクチャやドメインの型など、一連の型です。
- 次のファイルは最初のファイルにのみ依存します。これは下から2番目の層の機能を表します。
- 以下同様に続きます。各ファイルは前のファイルにのみ依存します。
パート1で議論したユースケースの例を参照すると:
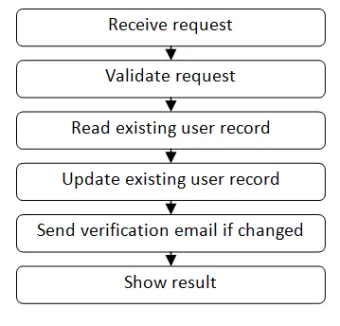
F#プロジェクトの対応するコードは次のようになるでしょう:

リストの一番下にあるのは、プログラムのエントリポイントを含む「main」または「program」と呼ばれるメインファイルです。
その直上にあるのは、アプリケーションのユースケースのコードです。このファイルのコードは、他のすべてのモジュールからの関数を「接着」して、特定のユースケースやサービスリクエストを表す単一の関数にまとめる場所です。(オブジェクト指向設計での最も近い等価物は「アプリケーションサービス」で、ほぼ同じ目的を果たします。)
そしてその上に「UI層」があり、その上に「DB層」があり、というように上に向かって続きます。
このアプローチの素晴らしい点は、コードベースに初めて触れる人でも、どこから始めればいいかが常にわかることです。最初の数ファイルは常にアプリケーションの「ボトムレイヤー」であり、最後の数ファイルは常に「トップレイヤー」です。フォルダは必要ありません!
コードをクラスではなくモジュールに配置する
Section titled “コードをクラスではなくモジュールに配置する”F#初心者からよくある質問は、「クラスを使わないでコードをどう整理すればいいの?」というものです。
答えは:モジュールです。ご存知の通り、オブジェクト指向プログラムでは、データ構造とそれに対する関数はクラスにまとめられます。しかし関数型スタイルのF#では、データ構造とそれに対する関数はモジュールに含まれます。
型と関数を混在させる一般的なパターンは3つあります:
- 型をその関数と同じモジュールで宣言する。
- 型を関数とは別に宣言するが、同じファイル内に配置する。
- 型を関数とは別に宣言し、異なるファイルに配置する。通常、型定義のみを含むファイルになります。
最初のアプローチでは、型はモジュール内部で関連する関数と一緒に定義されます。主要な型が1つだけの場合、「T」やモジュールの名前などのシンプルな名前がつけられることがよくあります。
例を示します:
namespace Example
// モジュールを宣言module Person =
type T = {First:string; Last:string}
// コンストラクタ let create first last = {First=first; Last=last}
// 型に対して動作するメソッド let fullName {First=first; Last=last} = first + " " + lastこの場合、関数はPerson.createやPerson.fullNameのような名前でアクセスされ、型自体はPerson.Tという名前でアクセスされます。
2番目のアプローチでは、型は同じファイル内で宣言されますが、モジュールの外部にあります:
namespace Example
// モジュールの外部で型を宣言type PersonType = {First:string; Last:string}
// 型に対して動作する関数のモジュールを宣言module Person =
// コンストラクタ let create first last = {First=first; Last=last}
// 型に対して動作するメソッド let fullName {First=first; Last=last} = first + " " + lastこの場合、関数は同じ名前(Person.createやPerson.fullName)でアクセスされますが、型自体はPersonTypeのような名前でアクセスされます。
最後に、3番目のアプローチを示します。型は特別な「型のみ」モジュールで宣言されます(通常、異なるファイルに配置):
// =========================// =========================namespace Example
// "型のみ"モジュール[<AutoOpen>]module DomainTypes =
type Person = {First:string; Last:string}
type OtherDomainType = ...
type ThirdDomainType = ...この特定の例では、AutoOpen属性が使用されており、このモジュールの型がプロジェクト内の他のすべてのモジュールに自動的に表示されるようになっています。つまり、「グローバル」にしています。
そして、別のモジュールにPerson型に対して動作するすべての関数が含まれています。
// =========================// =========================namespace Example
// 型に対して動作する関数のモジュールを宣言module Person =
// コンストラクタ let create first last = {First=first; Last=last}
// 型に対して動作するメソッド let fullName {First=first; Last=last} = first + " " + lastこの例では、型とモジュールの両方がPersonと呼ばれていることに注意してください。実際には、コンパイラは意図を理解できるので、通常は問題になりません。
たとえば、次のように書いた場合:
let f (p:Person) = p.FirstコンパイラはPerson型を参照していると理解します。
一方、次のように書いた場合:
let g () = Person.create "Alice" "Smith"コンパイラはPersonモジュールを参照していると理解します。
モジュールについての詳細は、関数の整理に関する記事を参照してください。
モジュールの整理
Section titled “モジュールの整理”このレシピでは、以下のガイドラインに従ってアプローチを混合して使用します:
モジュールのガイドライン
型が複数のモジュールで共有されている場合は、特別な型専用モジュールに配置する。
- たとえば、型がグローバルに使用される場合(より正確には、DDDで言う「境界づけられたコンテキスト」内で使用される場合)、
DomainTypesやDomainModelと呼ばれるモジュールに配置します。これはコンパイル順序の早い段階に来ます。 - 型がサブシステムでのみ使用される場合(例:複数のUIモジュールで共有される型)、
UITypesと呼ばれるモジュールに配置します。これは他のUIモジュールの直前のコンパイル順序に来ます。
型がモジュール(または2つ)に対してプライベートである場合は、関連する関数と同じモジュールに配置する。
- たとえば、バリデーションにのみ使用される型は
Validationモジュールに配置します。データベースアクセスにのみ使用される型はDatabaseモジュールに配置します。以下同様です。
もちろん、型を整理する方法は多数ありますが、これらのガイドラインは良い出発点となります。
フォルダはどこ?
Section titled “フォルダはどこ?”よくある不満は、F#プロジェクトがフォルダ構造をサポートしていないことで、これが大規模プロジェクトの整理を困難にしているという主張です。
純粋なオブジェクト指向設計を行っている場合、これは正当な不満です。しかし、上記の議論からわかるように、モジュールを線形リストにすることは、依存関係を正しく維持するのに非常に役立ちます(厳密には必要ではありませんが)。理論的には、ファイルを散らばらせてもコンパイラが正しいコンパイル順序を把握できるかもしれませんが、実際にはコンパイラがこの順序を決定するのは簡単ではありません。
さらに重要なのは、人間が正しい順序を決定するのも簡単ではないということです。そのため、メンテナンスが必要以上に困難になってしまいます。
実際には、大規模プロジェクトであっても、フォルダがないことは思ったほど問題にはなりません。F#コンパイラ自体を含め、この制限内で成功している大規模なF#プロジェクトがいくつかあります。詳細は実世界の循環依存とモジュール性に関する記事を参照してください。
型間に相互依存がある場合はどうすればいいですか?
Section titled “型間に相互依存がある場合はどうすればいいですか?”オブジェクト指向設計から移行する場合、次の例のような型間の相互依存に遭遇するかもしれません。これはコンパイルできません:
type Location = {name: string; workers: Employee list}
type Employee = {name: string; worksAt: Location}F#コンパイラを満足させるにはどうすればいいでしょうか?
それほど難しくはありませんが、さらに説明が必要なので、循環依存の対処法について別の記事を用意しました。
サンプルコード
Section titled “サンプルコード”これまでのコードを再確認しましょう。今回はモジュールに整理しています。
以下の各モジュールは、通常別々のファイルになります。
これはまだスケルトンにすぎないことに注意してください。いくつかのモジュールが欠けており、一部のモジュールはほとんど空です。
この種の整理は小規模プロジェクトでは過剰ですが、今後さらに多くのコードが追加されます!
/// ===========================================/// 複数のプロジェクトで共有される共通の型と関数/// ===========================================module CommonLibrary =
// 二進型 type Result<'TSuccess,'TFailure> = | Success of 'TSuccess | Failure of 'TFailure
// 単一の値を二進結果に変換する let succeed x = Success x
// 単一の値を二進結果に変換する let fail x = Failure x
// 成功関数または失敗関数のいずれかを適用する let either successFunc failureFunc twoTrackInput = match twoTrackInput with | Success s -> successFunc s | Failure f -> failureFunc f
// スイッチ関数を二進関数に変換する let bind f = either f fail
// 二進値をスイッチ関数にパイプする let (>>=) x f = bind f x
// 2つのスイッチを別のスイッチに合成する let (>=>) s1 s2 = s1 >> bind s2
// 単進関数をスイッチに変換する let switch f = f >> succeed
// 単進関数を二進関数に変換する let map f = either (f >> succeed) fail
// デッドエンド関数を単進関数に変換する let tee f x = f x; x
// 単進関数を例外処理付きのスイッチに変換する let tryCatch f exnHandler x = try f x |> succeed with | ex -> exnHandler ex |> fail
// 2つの単進関数を二進関数に変換する let doubleMap successFunc failureFunc = either (successFunc >> succeed) (failureFunc >> fail)
// 2つのスイッチを並列に追加する let plus addSuccess addFailure switch1 switch2 x = match (switch1 x),(switch2 x) with | Success s1,Success s2 -> Success (addSuccess s1 s2) | Failure f1,Success _ -> Failure f1 | Success _ ,Failure f2 -> Failure f2 | Failure f1,Failure f2 -> Failure (addFailure f1 f2)
/// ===========================================/// このプロジェクトのグローバル型/// ===========================================module DomainTypes =
open CommonLibrary
/// リクエストのDTO type Request = {name:string; email:string}
// 今後さらに多くの型が追加されます!
/// ===========================================/// ログ記録関数/// ===========================================module Logger =
open CommonLibrary open DomainTypes
let log twoTrackInput = let success x = printfn "DEBUG. 現在まで成功: %A" x; x let failure x = printfn "エラー. %A" x; x doubleMap success failure twoTrackInput
/// ===========================================/// バリデーション関数/// ===========================================module Validation =
open CommonLibrary open DomainTypes
let validate1 input = if input.name = "" then Failure "名前は空白にできません" else Success input
let validate2 input = if input.name.Length > 50 then Failure "名前は50文字以内にしてください" else Success input
let validate3 input = if input.email = "" then Failure "メールアドレスは空白にできません" else Success input
// バリデーション関数用の"plus"関数を作成 let (&&&) v1 v2 = let addSuccess r1 r2 = r1 // 最初のものを返す let addFailure s1 s2 = s1 + "、" + s2 // 連結 plus addSuccess addFailure v1 v2
let combinedValidation = validate1 &&& validate2 &&& validate3
let canonicalizeEmail input = { input with email = input.email.Trim().ToLower() }
/// ===========================================/// データベース関数/// ===========================================module CustomerRepository =
open CommonLibrary open DomainTypes
let updateDatabase input = () // 今のところダミーのデッドエンド関数
// 例外を処理する新しい関数 let updateDatebaseStep = tryCatch (tee updateDatabase) (fun ex -> ex.Message)
/// ===========================================/// すべてのユースケースまたはサービスを一箇所に/// ===========================================module UseCases =
open CommonLibrary open DomainTypes
let handleUpdateRequest = Validation.combinedValidation >> map Validation.canonicalizeEmail >> bind CustomerRepository.updateDatebaseStep >> Logger.logこの記事では、コードをモジュールに整理する方法を見てきました。このシリーズの次の記事では、いよいよ実際のコーディングを始めます!
それまでの間、循環依存についての続編をお読みください:
- 循環依存は悪
- 循環依存を取り除くリファクタリング
- 実世界の循環依存とモジュール性(C#とF#のプロジェクトの実際の指標を比較しています)