鉄道指向プログラミング
更新: より包括的なプレゼンテーションのスライドと動画はこちら(そして、Eitherモナドを理解している場合は、まずこれを読んでください)
前回の記事では、ユースケースをステップに分け、全てのエラーを別の失敗トラックに振り分ける方法を見ました。以下のような感じです。

この記事では、これらのステップ関数を1つの単位にまとめる様々な方法を見ていきます。関数の詳細な内部設計については、後の記事で説明します。
ステップを表す関数の設計
Section titled “ステップを表す関数の設計”これらのステップをもう少し詳しく見てみましょう。たとえば、検証関数はどのように動作するのでしょうか?データが入力されますが、何が出力されるのでしょうか?
2つの可能性があります。データが有効な場合(ハッピーパス)、または何か問題がある場合です。問題がある場合は失敗パスに進み、残りのステップをバイパスします。以下のようになります。

しかし、前回と同様、これは有効な関数ではありません。関数は1つの出力しか持てないので、前回定義したResult型を使う必要があります。
type Result<'TSuccess,'TFailure> = | Success of 'TSuccess | Failure of 'TFailureそして、図は次のようになります。

実際にどのように機能するかを示すために、実際の検証関数の例を挙げます。
type Request = {name:string; email:string}
let validateInput input = if input.name = "" then Failure "名前を空白にはできません" else if input.email = "" then Failure "メールアドレスを空白にはできません" else Success input // ハッピーパス関数の型を見ると、コンパイラはRequestを受け取り、成功の場合はRequest、失敗の場合はstringのResultを出力すると推論しています。
validateInput : Request -> Result<Request,string>フローの他のステップも同じように分析できます。各ステップは同じ「形」を持つことがわかります。つまり、何らかの入力と、Success/Failureの出力です。
先制的な謝罪:関数は2つの出力を持てないと言ったばかりですが、これ以降、「2つの出力」関数と呼ぶことがあるかもしれません!もちろん、関数の出力の形が2つのケースを持つという意味です。
鉄道指向プログラミング
Section titled “鉄道指向プログラミング”では、これらの「1つの入力 -> 成功/失敗出力」関数をたくさん持っていますが、どのようにつなげればよいでしょうか?
1つの関数のSuccess出力を次の関数の入力につなぎ、Failure出力の場合は2番目の関数をバイパスする方法が必要です。この図が全体的なアイデアを示しています。

これを行うための素晴らしい類推があります。おそらくすでに馴染みのあるものです。鉄道です!
鉄道には列車を別の線路に導くための分岐器(イギリスでは「ポイント」)があります。これらの「成功/失敗」関数を鉄道の分岐器と考えることができます。このようになります。
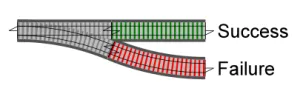
そして、ここに2つの分岐器が並んでいます。
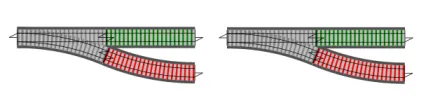
両方の失敗トラックをつなげるにはどうすればよいでしょうか?明らかです。このようにします!

そして、一連の分岐器があれば、次のような2線式のシステムになります。

上の線路がハッピーパスで、下の線路が失敗パスです。
全体像を見ると、2線式の鉄道をまたぐ一連のブラックボックス関数があり、各関数がデータを処理して次の関数に渡していくことがわかります。

しかし、関数の中を見ると、実際には各関数の中に分岐器があり、不正なデータを失敗トラックに振り分けていることがわかります。

失敗パスに入ると、(通常は)二度とハッピーパスに戻ることはなく、最後まで残りの関数をバイパスすることに注意してください。
基本的な合成
Section titled “基本的な合成”ステップ関数を「接着」する方法を議論する前に、合成がどのように機能するかを復習しましょう。
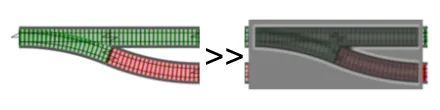
標準的な関数を、1線式の鉄道の上に座るブラックボックス(たとえばトンネル)だと想像してください。1つの入力と1つの出力があります。
一連の1線式関数をつなげたい場合、左から右への合成演算子>>を使えます。

同じ合成操作は2線式関数にも適用できます。

合成の唯一の制約は、左側の関数の出力型が右側の関数の入力型と一致する必要があることです。
鉄道の類推では、1線式の出力を1線式の入力に接続したり、2線式の出力を2線式の入力に接続したりできますが、2線式の出力を1線式の入力に直接接続することはできません。

分岐器を2線式入力に変換する
Section titled “分岐器を2線式入力に変換する”ここで問題に直面しました。
各ステップの関数は1つの入力トラックを持つ分岐器になります。しかし、全体のフローには2線式のシステムが必要で、各関数が両方のトラックにまたがる必要があります。つまり、各関数は単純な1線式入力(Request)ではなく、2線式入力(前の関数が出力したResult)を持つ必要があります。
分岐器を2線式システムに挿入するにはどうすればよいでしょうか?
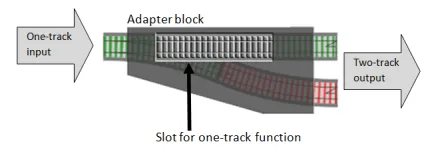
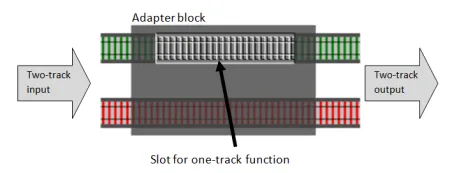
答えは簡単です。分岐器関数用の「穴」や「スロット」を持つ「アダプター」関数を作成し、それを適切な2線式関数に変換します。以下は図解です。
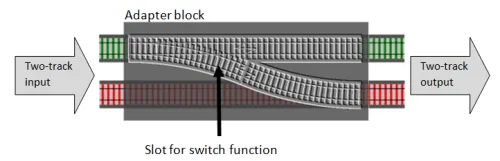
そして、実際のコードは次のようになります。このアダプター関数をbindと呼びますが、これは標準的な名前です。
let bind switchFunction = fun twoTrackInput -> match twoTrackInput with | Success s -> switchFunction s | Failure f -> Failure fbind関数はスイッチ関数をパラメータとして受け取り、新しい関数を返します。新しい関数は2線式入力(Result型)を受け取り、各ケースをチェックします。入力がSuccessの場合、switchFunctionを値で呼び出します。入力がFailureの場合、スイッチ関数はバイパスされます。
これをコンパイルして関数のシグネチャを見てみましょう。
val bind : ('a -> Result<'b,'c>) -> Result<'a,'c> -> Result<'b,'c>このシグネチャを解釈する一つの方法は、bind関数がスイッチ関数('a -> Result<..>)を1つのパラメータとして持ち、完全な2線式関数(Result<..> -> Result<..>)を出力として返すということです。
より具体的に言えば、
- bindのパラメータ(
switchFunction)は何らかの型'aを受け取り、'b型(成功トラック用)と'c型(失敗トラック用)のResultを出力します。 - 返される関数自体はパラメータ(
twoTrackInput)を持ち、これは'a型(成功用)と'c型(失敗用)のResultです。型'aはswitchFunctionが1線式で期待するものと同じである必要があります。 - 返される関数の出力は別の
Resultで、今度は'b型(成功用)と'c型(失敗用)です。これはスイッチ関数の出力と同じ型です。
考えてみれば、この型シグネチャはまさに期待通りのものです。
この関数は完全に汎用的であり、どんなスイッチ関数やどんな型でも機能することに注意してください。関数が気にするのは、関与する実際の型ではなく、switchFunctionの「形」だけです。
bind関数を書く他の方法
Section titled “bind関数を書く他の方法”ちなみに、このような関数を書く他の方法もあります。
1つの方法は、内部関数を定義する代わりに、twoTrackInputの明示的な2番目のパラメータを使うことです。このようになります。
let bind switchFunction twoTrackInput = match twoTrackInput with | Success s -> switchFunction s | Failure f -> Failure fこれは最初の定義とまったく同じです。2つのパラメータを持つ関数が1つのパラメータを持つ関数とどうして全く同じになるのか疑問に思うなら、カリー化に関する記事を読む必要があります!
もう1つの方法は、match..with構文をより簡潔なfunctionキーワードに置き換えることです。このようになります。
let bind switchFunction = function | Success s -> switchFunction s | Failure f -> Failure f他のコードでこれら3つのスタイルすべてを見かけるかもしれませんが、個人的には2番目のスタイル(let bind switchFunction twoTrackInput = )が好みです。明示的なパラメータを使うことで、専門家でない人にとってもコードが読みやすくなると思うからです。
例: いくつかの検証関数の組み合わせ
Section titled “例: いくつかの検証関数の組み合わせ”ここで、概念をテストするために少しコードを書いてみましょう。
まず、すでに定義したものから始めましょう。Request、Result、そしてbindです。
type Result<'TSuccess,'TFailure> = | Success of 'TSuccess | Failure of 'TFailure
type Request = {name:string; email:string}
let bind switchFunction twoTrackInput = match twoTrackInput with | Success s -> switchFunction s | Failure f -> Failure f次に、3つの検証関数を作成します。それぞれが「分岐器」関数で、これらを1つの大きな関数に組み合わせることが目標です。
let validate1 input = if input.name = "" then Failure "名前を空白にはできません" else Success input
let validate2 input = if input.name.Length > 50 then Failure "名前は50文字以内にしてください" else Success input
let validate3 input = if input.email = "" then Failure "メールアドレスを空白にはできません" else Success inputこれらを組み合わせるには、各検証関数にbindを適用して、2線式の入力を受け付ける新しい代替関数を作成します。
そして、標準的な関数合成を使って2線式の関数をつなげることができます。このようになります。
/// 3つの検証関数をつなげるlet combinedValidation = // 分岐器から2線式入力に変換 let validate2' = bind validate2 let validate3' = bind validate3 // 2線式をつなげる validate1 >> validate2' >> validate3'validate2'とvalidate3'はResultを受け取りResultを返す新しい関数です。シグネチャを見るとそれがわかります。
しかし、validate1は2線式入力に変換する必要がありません。その入力は1線式のままで、出力は既に合成に必要な2線式になっています。
以下は、(バインドされていない)Validate1分岐器と、Validate2およびValidate3分岐器、さらにValidate2'およびValidate3'アダプターを示す図です。

bindを「インライン化」して、このように書くこともできます。
let combinedValidation = // 2線式をつなげる validate1 >> bind validate2 >> bind validate32つの不正な入力と1つの正しい入力でテストしてみましょう。
// テスト1let input1 = {name=""; email=""}combinedValidation input1|> printfn "Result1=%A"
// ==> Result1=Failure "名前を空白にはできません"
// テスト2let input2 = {name="Alice"; email=""}combinedValidation input2|> printfn "Result2=%A"
// ==> Result2=Failure "メールアドレスを空白にはできません"
// テスト3let input3 = {name="Alice"; email="good"}combinedValidation input3|> printfn "Result3=%A"
// ==> Result3=Success {name = "Alice"; email = "good";}ぜひ自分で試して、検証関数とテスト入力をいろいろ変えて遊んでみてください。
3つの検証を並列で実行して、すべての検証エラーを一度に取得する方法はないのかと疑問に思うかもしれません。 はい、その方法はあります。この記事の後半で説明します。
パイピング操作としてのbind
Section titled “パイピング操作としてのbind”bind関数について議論している間に、分岐器関数に値をパイプするために使われる一般的な記号>>=があります。
以下は定義で、2つのパラメータを入れ替えてチェーンしやすくしています。
/// 中置演算子を作成let (>>=) twoTrackInput switchFunction = bind switchFunction twoTrackInputこの記号を覚えるための一つの方法は、合成記号>>の後に2線式の鉄道記号=が続くと考えることです。
このように使うと、>>=演算子は一種のパイプ(|>)ですが、分岐器関数用です。
通常のパイプでは、左側は1線式の値で、右側は通常の関数です。 しかし、「bindパイプ」操作では、左側は2線式の値で、右側は分岐器関数です。
これを使ってcombinedValidation関数の別の実装を作成してみましょう。
let combinedValidation x = x |> validate1 // validate1は1線式入力を持つので通常のパイプ // しかしvalidate1の結果は2線式出力になる... >>= validate2 // ...そのため「bindパイプ」を使う。結果は再び2線式出力 >>= validate3 // ...そのためもう一度「bindパイプ」を使うこの実装と前の実装の違いは、この定義が関数指向ではなくデータ指向だということです。初期データ値のための明示的なパラメータxがあります。xは最初の関数に渡され、その出力が2番目の関数に渡され、というように続きます。
前の実装(以下に再掲)では、データのパラメータは全くありませんでした!焦点は関数自体にあり、それを流れるデータにはありませんでした。
let combinedValidation = validate1 >> bind validate2 >> bind validate3bindの代替手法
Section titled “bindの代替手法”分岐器を組み合わせるもう一つの方法は、2線式入力に適応させるのではなく、単純に直接つなげて新しい、より大きな分岐器を作ることです。
つまり、これが:
このようになります:
しかし、よく考えてみると、この組み合わせたトラックも実際には別の分岐器にすぎません!中央部分を隠すとわかります。1つの入力と2つの出力があります:

つまり、実際に行ったのは分岐器の一種の合成で、このようになります:

各合成の結果は単なる別の分岐器なので、常に別の分岐器を追加でき、さらに大きなものになりますが、それでもまだ分岐器であり、このように続きます。
以下は分岐器合成のコードです。標準的に使われる記号は>=>で、通常の合成記号に似ていますが、角括弧の間に鉄道トラックがあります。
let (>=>) switch1 switch2 x = match switch1 x with | Success s -> switch2 s | Failure f -> Failure fここでも、実際の実装は非常に単純です。1線式入力xを最初の分岐器に通します。成功した場合、結果を2番目の分岐器に渡し、それ以外の場合は2番目の分岐器を完全にバイパスします。
これでcombinedValidation関数を、bindではなく分岐器合成を使って書き直すことができます:
let combinedValidation = validate1 >=> validate2 >=> validate3これがこれまでで最もシンプルだと思います。もちろん、拡張も簡単です。4番目の検証関数がある場合、単純に最後に追加するだけです。
bindと分岐器合成の比較
Section titled “bindと分岐器合成の比較”一見似ているように見える2つの異なる概念があります。何が違うのでしょうか?
おさらいすると:
- Bindは1つの分岐器関数パラメータを持ちます。分岐器関数を完全な2線式関数(2線式入力と2線式出力を持つ)に変換するアダプターです。
- 分岐器合成は2つの分岐器関数パラメータを持ちます。これらを直列に組み合わせて別の分岐器関数を作ります。
では、分岐器合成ではなくbindを使う理由は何でしょうか?コンテキストによります。既存の2線式システムがあり、そこに分岐器を挿入する必要がある場合、 bindをアダプターとして使用して、分岐器を2線式入力を受け付けるものに変換する必要があります。
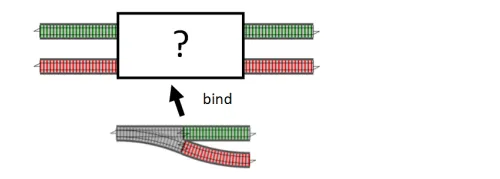
一方、データフロー全体が一連の分岐器で構成されている場合、分岐器合成の方がシンプルかもしれません。
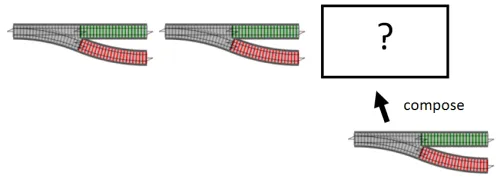
bindを使った分岐器合成
Section titled “bindを使った分岐器合成”実は、分岐器合成はbindを使って書くこともできます。最初の分岐器をbindで適応した2番目の分岐器とつなげると、分岐器合成と同じ結果が得られます:
これが2つの別々の分岐器です:
そして、これが分岐器を組み合わせて新しい大きな分岐器を作ったものです:
そして、これが2番目の分岐器にbindを使って同じことを行ったものです:
以下は、このような考え方で書き直した分岐器合成演算子です:
let (>=>) switch1 switch2 = switch1 >> (bind switch2)この分岐器合成の実装は最初のものよりもはるかにシンプルですが、より抽象的でもあります。初心者にとってこちらの方が理解しやすいかどうかは別の問題です!関数をデータの導管としてだけでなく、それ自体で独立したものとして考えるようになれば、このアプローチの理解がより容易になると思います。
単純な関数を鉄道指向プログラミングモデルに変換する
Section titled “単純な関数を鉄道指向プログラミングモデルに変換する”慣れてくれば、このモデルにさまざまなものを当てはめることができます。
たとえば、分岐器ではない、ただの通常の関数があるとします。そして、それをフローに挿入したいとします。
実際の例を挙げましょう。検証が完了した後にメールアドレスをトリムして小文字に変換したいとします。これを行うコードは次のようになります:
let canonicalizeEmail input = { input with email = input.email.Trim().ToLower() }このコードは(1線式の)Requestを受け取り、(1線式の)Requestを返します。
これを検証ステップの後、更新ステップの前に挿入するにはどうすればよいでしょうか?
この単純な関数を分岐器関数に変換できれば、先ほど説明した分岐器合成を使うことができます。
言い換えれば、アダプターブロックが必要です。bindで使用したのと同じ概念ですが、今回のアダプターブロックは1線式関数用のスロットを持ち、アダプターブロック全体の「形」は分岐器になります。
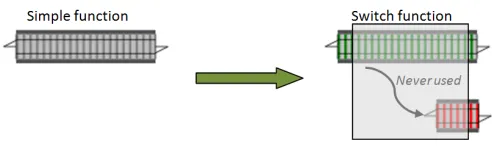
これを行うコードは些細なものです。1線式関数の出力を取り、2線式の結果に変換するだけです。この場合、結果は常にSuccessになります。
// 通常の関数を分岐器に変換するlet switch f x = f x |> Success鉄道の観点から言えば、失敗トラックを少し追加したことになります。全体として見ると、分岐器関数(1線式入力、2線式出力)のように見えますが、 もちろん、失敗トラックはダミーで、分岐器が実際に使われることはありません。
switchが利用可能になれば、canonicalizeEmail関数をチェーンの末尾に簡単に追加できます。拡張し始めているので、関数名をusecaseに変更しましょう。
let usecase = validate1 >=> validate2 >=> validate3 >=> switch canonicalizeEmailテストして何が起こるか見てみましょう:
let goodInput = {name="Alice"; email="UPPERCASE "}usecase goodInput|> printfn "Canonicalize Good Result = %A"
//Canonicalize Good Result = Success {name = "Alice"; email = "uppercase";}
let badInput = {name=""; email="UPPERCASE "}usecase badInput|> printfn "Canonicalize Bad Result = %A"
//Canonicalize Bad Result = Failure "名前を空白にはできません"1線式関数から2線式関数を作成する
Section titled “1線式関数から2線式関数を作成する”前の例では、1線式関数を取り、それから分岐器を作成しました。これにより、分岐器合成をその関数に使用できるようになりました。
しかし、時には2線式モデルを直接使いたい場合があります。その場合、1線式関数を直接2線式関数に変換したいでしょう。
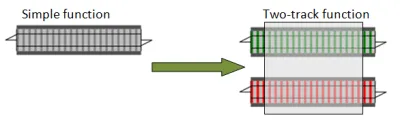
ここでも、単純な関数用のスロットを持つアダプターブロックが必要です。このアダプターを通常mapと呼びます。
そして、ここでも実際の実装は非常に単純です。2線式入力がSuccessの場合、関数を呼び出し、その出力をSuccessに変換します。一方、2線式入力がFailureの場合、関数を完全にバイパスします。
以下がコードです:
// 通常の関数を2線式関数に変換するlet map oneTrackFunction twoTrackInput = match twoTrackInput with | Success s -> Success (oneTrackFunction s) | Failure f -> Failure fそして、これをcanonicalizeEmailで使用すると次のようになります:
let usecase = validate1 >=> validate2 >=> validate3 >> map canonicalizeEmail // 通常の合成ここで通常の合成が使われていることに注意してください。map canonicalizeEmailは完全な2線式関数であり、validate3分岐器の出力に直接接続できるからです。
言い換えれば、1線式関数の場合、>=> switchは>> mapとまったく同じです。選択はあなた次第です。
デッドエンド関数を2線式関数に変換する
Section titled “デッドエンド関数を2線式関数に変換する”私たちがよく扱いたいもう一つの関数は「デッドエンド」関数です。これは入力を受け取りますが、有用な出力を持たない関数です。
たとえば、データベースレコードを更新する関数を考えてみましょう。これは副作用のためにのみ有用で、通常は何も返しません。
このような関数をフローに組み込むにはどうすればよいでしょうか?
私たちがする必要があるのは:
- 入力のコピーを保存する。
- 関数を呼び出し、出力があってもそれを無視する。
- チェーン内の次の関数に渡すために元の入力を返す。
鉄道の観点から見ると、これはデッドエンドの側線を作ることに相当します。このようになります。
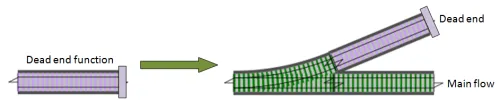
これを機能させるには、switchのような別のアダプター関数が必要です。ただし、今回は1線式デッドエンド関数用のスロットがあり、それを1線式出力を持つ単一の1線式パススルー関数に変換します。
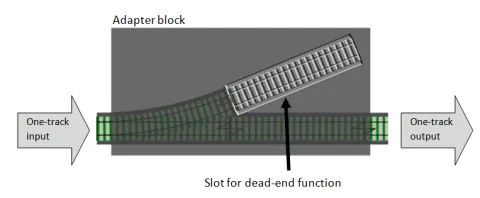
以下がコードで、UNIXのteeコマンドにちなんでteeと呼びます:
let tee f x = f x |> ignore xデッドエンド関数を単純な1線式パススルー関数に変換したら、前述のswitchやmapを使ってデータフローで使用できます。
以下は「分岐器合成」スタイルで使用したコードです:
// デッドエンド関数let updateDatabase input = () // 今はダミーのデッドエンド関数
let usecase = validate1 >=> validate2 >=> validate3 >=> switch canonicalizeEmail >=> switch (tee updateDatabase)あるいは、switchを使って>=>で接続する代わりに、mapを使って>>で接続することもできます。
以下は「2線式」スタイルで通常の合成を使用した別の実装で、まったく同じです:
let usecase = validate1 >> bind validate2 >> bind validate3 >> map canonicalizeEmail >> map (tee updateDatabase)デッドエンドのデータベース更新は何も返さないかもしれませんが、例外をスローしないとは限りません。クラッシュする代わりに、その例外をキャッチして失敗に変換したいと思います。
コードはswitch関数に似ていますが、例外をキャッチします。これをtryCatchと呼びましょう:
let tryCatch f x = try f x |> Success with | ex -> Failure ex.Messageそして、これはデータベース更新コードにswitchの代わりにtryCatchを使用した修正版のデータフローです。
let usecase = validate1 >=> validate2 >=> validate3 >=> switch canonicalizeEmail >=> tryCatch (tee updateDatabase)2線式入力を持つ関数
Section titled “2線式入力を持つ関数”これまで見てきた関数はすべて1つの入力しか持っていません。なぜなら、常にハッピーパスを流れるデータだけを扱うからです。
しかし、時には両方のトラックを扱う関数が必要な場合があります。たとえば、成功と失敗の両方をログに記録する関数などです。
これまでと同様に、アダプターブロックを作成しますが、今回は2つの別々の1線式関数用のスロットを持ちます。
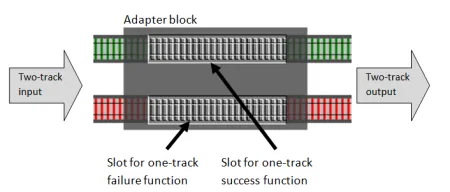
以下がコードです:
let doubleMap successFunc failureFunc twoTrackInput = match twoTrackInput with | Success s -> Success (successFunc s) | Failure f -> Failure (failureFunc f)ちなみに、この関数を使って、失敗関数にidを使用することで、mapのよりシンプルなバージョンを作ることができます:
let map successFunc = doubleMap successFunc iddoubleMapを使ってデータフローにログ記録を挿入してみましょう:
let log twoTrackInput = let success x = printfn "デバッグ: ここまで成功: %A" x; x let failure x = printfn "エラー: %A" x; x doubleMap success failure twoTrackInput
let usecase = validate1 >=> validate2 >=> validate3 >=> switch canonicalizeEmail >=> tryCatch (tee updateDatabase) >> log以下はテストコードと結果です:
let goodInput = {name="Alice"; email="good"}usecase goodInput|> printfn "良好な結果 = %A"
// デバッグ: ここまで成功: {name = "Alice"; email = "good";}// 良好な結果 = Success {name = "Alice"; email = "good";}
let badInput = {name=""; email=""}usecase badInput|> printfn "不良な結果 = %A"
// エラー: "名前を空白にはできません"// 不良な結果 = Failure "名前を空白にはできません"単一の値を2線式の値に変換する
Section titled “単一の値を2線式の値に変換する”完全を期すために、単純な単一の値を2線式の値(成功または失敗)に変換する簡単な関数も作成しておきましょう。
let succeed x = Success x
let fail x = Failure x現時点ではこれらは些細なもので、単にResult型のコンストラクタを呼び出しているだけです。しかし、本格的なコーディングに入ると、共用体ケースのコンストラクタを直接使用するのではなく、これらを使用することで、裏側の変更から自分たちを隔離できることがわかるでしょう。
関数を並列に組み合わせる
Section titled “関数を並列に組み合わせる”これまで、関数を直列に組み合わせてきました。しかし、検証のような場合、複数の分岐器を並列に実行し、結果を組み合わせたいことがあります。このようなイメージです:
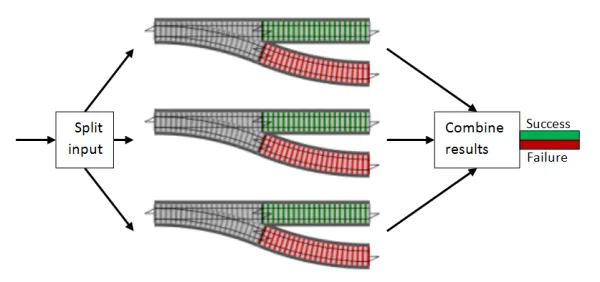
これを簡単にするために、分岐器合成で使ったのと同じトリックを再利用できます。一度に多くを行うのではなく、単一のペアに焦点を当て、それらを「加算」して新しい分岐器を作れば、その後「加算」を簡単にチェーンして、必要な数だけ加算できます。つまり、これを実装するだけで良いのです:
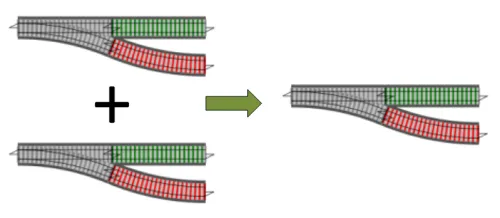
では、並列に2つの分岐器を加算するロジックはどうなるでしょうか?
- まず、入力を取り、各分岐器に適用します。
- 次に両方の分岐器の出力を見て、両方が成功なら全体の結果は
Successになります。 - どちらかの出力が失敗なら、全体の結果も
Failureになります。
以下が関数で、これをplusと呼びましょう:
let plus switch1 switch2 x = match (switch1 x),(switch2 x) with | Success s1,Success s2 -> Success (s1 + s2) | Failure f1,Success _ -> Failure f1 | Success _ ,Failure f2 -> Failure f2 | Failure f1,Failure f2 -> Failure (f1 + f2)しかし、ここで新しい問題が出てきました。2つの成功、または2つの失敗をどう扱えばよいでしょうか?内部の値をどのように組み合わせればよいでしょうか?
上の例ではs1 + s2とf1 + f2を使いましたが、これは何らかの+演算子が使えることを意味します。文字列や整数の場合はそうかもしれませんが、一般的にはそうではありません。
値を組み合わせる方法は異なるコンテキストで変わる可能性があるので、一度に全てを解決しようとするのではなく、必要な関数を呼び出し元に渡してもらうことにしましょう。
以下が書き直したバージョンです:
let plus addSuccess addFailure switch1 switch2 x = match (switch1 x),(switch2 x) with | Success s1,Success s2 -> Success (addSuccess s1 s2) | Failure f1,Success _ -> Failure f1 | Success _ ,Failure f2 -> Failure f2 | Failure f1,Failure f2 -> Failure (addFailure f1 f2)部分適用を助けるために、これらの新しい関数をパラメータリストの最初に置きました。
並列検証の実装
Section titled “並列検証の実装”では、検証関数用の「plus」の実装を作成しましょう。
- 両方の関数が成功した場合、変更されていないリクエストを返すので、
addSuccess関数はどちらかのパラメータを返せば良いです。 - 両方の関数が失敗した場合、異なる文字列を返すので、
addFailure関数はそれらを連結すべきです。
したがって、検証の場合、「plus」操作は「AND」関数のようなものです。両方の部分が「真」の場合にのみ結果が「真」になります。
これは自然に&&を演算子として使いたくなりますが、残念ながら&&は予約されています。しかし、&&&を使うことができます。このようになります:
// 検証関数用の「plus」関数を作成let (&&&) v1 v2 = let addSuccess r1 r2 = r1 // 最初のものを返す let addFailure s1 s2 = s1 + "; " + s2 // 連結 plus addSuccess addFailure v1 v2そして、&&&を使って、3つの小さな検証を組み合わせた単一の検証関数を作成できます:
let combinedValidation = validate1 &&& validate2 &&& validate3では、以前と同じテストを試してみましょう:
// テスト1let input1 = {name=""; email=""}combinedValidation input1|> printfn "結果1=%A"// ==> 結果1=Failure "名前を空白にはできません; メールアドレスを空白にはできません"
// テスト2let input2 = {name="Alice"; email=""}combinedValidation input2|> printfn "結果2=%A"// ==> 結果2=Failure "メールアドレスを空白にはできません"
// テスト3let input3 = {name="Alice"; email="good"}combinedValidation input3|> printfn "結果3=%A"// ==> 結果3=Success {name = "Alice"; email = "good";}最初のテストでは、2つの検証エラーが単一の文字列に結合されています。まさに私たちが望んでいたものです。
次に、以前の3つの個別の検証関数の代わりにusecase関数を使用して、メインのデータフロー関数を整理できます:
let usecase = combinedValidation >=> switch canonicalizeEmail >=> tryCatch (tee updateDatabase)そして、これをテストすると、成功がすべて最後まで流れ、メールアドレスが小文字化されトリムされていることがわかります:
// テスト4let input4 = {name="Alice"; email="UPPERCASE "}usecase input4|> printfn "結果4=%A"// ==> 結果4=Success {name = "Alice"; email = "uppercase";}検証関数をORで結合する方法も作れるのではないかと疑問に思うかもしれません。つまり、どちらかの部分が有効であれば全体の結果も有効になるようなものです。答えはもちろんイエスです。試してみてください!この場合は|||という記号を使うことをお勧めします。
関数の動的な挿入
Section titled “関数の動的な挿入”設定や、場合によってはデータの内容に基づいて、フローに関数を動的に追加または削除したいこともあるでしょう。
最も簡単な方法は、ストリームに挿入する2線式関数を作成し、必要ない場合はid関数に置き換えることです。
アイデアは以下のとおりです:
let injectableFunction = if config.debug then debugLogger else id実際のコードで試してみましょう:
type Config = {debug:bool}
let debugLogger twoTrackInput = let success x = printfn "デバッグ: ここまで成功: %A" x; x let failure = id // ここではログを記録しない doubleMap success failure twoTrackInput
let injectableLogger config = if config.debug then debugLogger else id
let usecase config = combinedValidation >> map canonicalizeEmail >> injectableLogger config以下は使用例です:
let input = {name="Alice"; email="good"}
let releaseConfig = {debug=false}input|> usecase releaseConfig|> ignore
// 出力なし
let debugConfig = {debug=true}input|> usecase debugConfig|> ignore
// デバッグ出力// デバッグ: ここまで成功: {name = "Alice"; email = "good";}鉄道トラック関数:ツールキット
Section titled “鉄道トラック関数:ツールキット”ここで一歩下がって、これまでの内容を振り返ってみましょう。
鉄道トラックを比喩として使い、あらゆるデータフロー型アプリケーションで機能する有用なビルディングブロックを作成しました。
関数を大まかに以下のように分類できます:
- **「コンストラクタ」**は新しいトラックを作成するために使用されます。
- **「アダプタ」**は1種類のトラックを別の種類のトラックに変換します。
- **「コンバイナ」**はトラックのセクションをリンクして、より大きなトラックを作ります。
これらの関数は、緩く言えばコンビネータライブラリを形成します。 つまり、型(ここでは鉄道トラックで表現される)と連携するように設計された関数のグループで、小さな部品を適応させたり組み合わせたりして、より大きな部品を構築することを設計目標としています。
bind、map、plusなどの関数は、あらゆる種類の関数型プログラミングシナリオで出てきます。そのため、これらを関数型パターンと考えることができます。これらは、「ビジター」、「シングルトン」、「ファサード」などのオブジェクト指向パターンに似ていますが、同じではありません。
以下にすべてをまとめて示します:
| 概念 | 説明 |
|---|---|
succeed |
1線式の値を受け取り、成功ブランチに2線式の値を作成するコンストラクタ。他のコンテキストではreturnやpureとも呼ばれることがあります。 |
fail |
1線式の値を受け取り、失敗ブランチに2線式の値を作成するコンストラクタ。 |
bind |
分岐器関数を受け取り、2線式の値を入力として受け付ける新しい関数を作成するアダプタ。 |
>>= |
2線式の値を分岐器関数にパイプするためのbindの中置版。 |
>> |
通常の合成。2つの通常関数を受け取り、それらを直列に接続して新しい関数を作成するコンバイナ。 |
>=> |
分岐器の合成。2つの分岐器関数を受け取り、それらを直列に接続して新しい分岐器関数を作成するコンバイナ。 |
switch |
通常の1線式関数を受け取り、分岐器関数に変換するアダプタ。(一部のコンテキストでは「リフト」としても知られています。) |
map |
通常の1線式関数を受け取り、2線式関数に変換するアダプタ。(一部のコンテキストでは「リフト」としても知られています。) |
tee |
デッドエンド関数を受け取り、データフローで使用できる1線式関数に変換するアダプタ。(tapとしても知られています。) |
tryCatch |
通常の1線式関数を受け取り、分岐器関数に変換するアダプタですが、例外もキャッチします。 |
doubleMap |
2つの1線式関数を受け取り、1つの2線式関数に変換するアダプタ。(bimapとしても知られています。) |
plus |
2つの分岐器関数を受け取り、それらを「並列」に結合し、結果を「加算」して新しい分岐器関数を作成するコンバイナ。(他のコンテキストでは++や<+>としても知られています。) |
&&& |
検証関数専用に調整された「plus」コンバイナで、二項ANDをモデルにしています。 |
鉄道トラック関数:完全なコード
Section titled “鉄道トラック関数:完全なコード”以下は、すべての関数を一箇所にまとめた完全なコードです。
上記で紹介したオリジナルのコードから若干の調整を行いました:
- ほとんどの関数が
eitherと呼ばれるコア関数を使用して定義されるようになりました。 tryCatchに例外ハンドラ用の追加パラメータが与えられました。
// 2線式の型type Result<'TSuccess,'TFailure> = | Success of 'TSuccess | Failure of 'TFailure
// 単一の値を2線式の結果に変換するlet succeed x = Success x
// 単一の値を2線式の結果に変換するlet fail x = Failure x
// 成功関数または失敗関数のいずれかを適用するlet either successFunc failureFunc twoTrackInput = match twoTrackInput with | Success s -> successFunc s | Failure f -> failureFunc f
// 分岐器関数を2線式関数に変換するlet bind f = either f fail
// 2線式の値を分岐器関数にパイプするlet (>>=) x f = bind f x
// 2つの分岐器を別の分岐器に合成するlet (>=>) s1 s2 = s1 >> bind s2
// 1線式関数を分岐器に変換するlet switch f = f >> succeed
// 1線式関数を2線式関数に変換するlet map f = either (f >> succeed) fail
// デッドエンド関数を1線式関数に変換するlet tee f x = f x; x
// 1線式関数を例外処理付きの分岐器に変換するlet tryCatch f exnHandler x = try f x |> succeed with | ex -> exnHandler ex |> fail
// 2つの1線式関数を2線式関数に変換するlet doubleMap successFunc failureFunc = either (successFunc >> succeed) (failureFunc >> fail)
// 2つの分岐器を並列に追加するlet plus addSuccess addFailure switch1 switch2 x = match (switch1 x),(switch2 x) with | Success s1,Success s2 -> Success (addSuccess s1 s2) | Failure f1,Success _ -> Failure f1 | Success _ ,Failure f2 -> Failure f2 | Failure f1,Failure f2 -> Failure (addFailure f1 f2)型 vs. 形
Section titled “型 vs. 形”ここまで、トラックの形にのみ焦点を当て、列車が運ぶ貨物については全く触れていませんでした。
これは魔法の鉄道で、運ばれる商品は各トラックを通過する際に魔法のように変化します。
たとえば、パイナップルの貨物はfunction1というトンネルを通過すると、魔法のようにリンゴに変わります。

そして、リンゴの貨物はfunction2というトンネルを通過すると、バナナに変わります。

この魔法の鉄道には重要なルールがあります。同じ種類の貨物を運ぶトラックしか接続できないのです。
この場合、function1とfunction2を接続できます。なぜなら、function1から出てくる貨物(リンゴ)がfunction2に入る貨物(同じくリンゴ)と同じだからです。

もちろん、トラックが常に同じ貨物を運ぶわけではありません。貨物の種類の不一致はエラーの原因となります。
しかし、これまでの議論で貨物に一度も触れていないことにお気づきでしょう!代わりに、1線式と2線式の関数について話すことに全ての時間を費やしてきました。
もちろん、貨物が一致しなければならないことは言うまでもありません。しかし、本当に重要なのは貨物ではなく、トラックの形であることがおわかりいただけたと思います。
ジェネリック型は強力
Section titled “ジェネリック型は強力”なぜ貨物の型を気にしなかったのでしょうか?それは、すべての「アダプタ」と「コンバイナ」関数が完全にジェネリックだからです!bindやmap、switch、plus関数は、貨物の型を気にせず、トラックの形だけを気にします。
非常にジェネリックな関数を持つことは2つの点で利点があります。1つ目の利点は明白です:関数がより汎用的であればあるほど、再利用性が高くなります。bindの実装は(形が正しければ)どんな型でも機能します。
しかし、ジェネリック関数のもう1つの、より微妙な側面もあります。関与する型について一般的に何も知らないため、できることとできないことが非常に制限されます。結果として、バグを導入することができないのです!
これが何を意味するか見てみましょう。mapのシグネチャを見てみましょう:
val map : ('a -> 'b) -> (Result<'a,'c> -> Result<'b,'c>)これは関数パラメータ'a -> 'bと値Result<'a,'c>を受け取り、値Result<'b,'c>を返します。
型'a、'b、'cについて何も知りません。知っているのは以下のことだけです:
- 同じ型
'aが関数パラメータと最初のResultのSuccessケースの両方に現れる。 - 同じ型
'bが関数パラメータと2番目のResultのSuccessケースの両方に現れる。 - 同じ型
'cが両方のResultのFailureケースに現れるが、関数パラメータには現れない。
ここから何がわかるでしょうか?
戻り値には型'bが含まれています。しかし、それはどこから来るのでしょうか?型'bが何なのかわからないので、作り方がわかりません。しかし、関数パラメータは作り方を知っています!'aを与えれば、'bを作ってくれます。
では、'aはどこから得られるでしょうか?型'aが何なのかもわからないので、これも作り方がわかりません。しかし、最初の結果パラメータには使える'aがあるので、Result<'a,'c>パラメータからSuccessの値を取り出し、それを関数パラメータに渡すしかないことがわかります。そして、Result<'b,'c>戻り値のSuccessケースは必ず関数の結果から構築されなければなりません。
最後に、同じロジックが'cにも適用されます。Result<'a,'c>入力パラメータからFailureの値を取り出し、それを使ってResult<'a,'c>戻り値のFailureケースを構築するしかありません。
つまり、基本的に*map関数を実装する方法は1つしかない*のです!型シグネチャが非常にジェネリックなので、選択の余地がありません。
一方で、map関数が必要な型について非常に具体的だったと想像してみてください:
val map : (int -> int) -> (Result<int,int> -> Result<int,int>)この場合、非常に多くの異なる実装を思いつくことができます。いくつか挙げてみましょう:
- 成功トラックと失敗トラックを入れ替えることができます。
- 成功トラックにランダムな数を加えることができます。
- 関数パラメータを完全に無視し、成功トラックと失敗トラックの両方でゼロを返すことができます。
これらの実装はすべて、期待することを行わないという意味で「バグがある」と言えます。しかし、これらがすべて可能なのは、型がintであることを事前に知っているからで、そのため値を本来あるべきではない方法で操作できるのです。型について知っていることが少ないほど、間違いを犯す可能性は低くなります。
ほとんどの関数で、変換は成功トラックにのみ適用されます。失敗トラックはそのまま残されるか(map)、入ってくる失敗とマージされます(bind)。
これは、失敗トラックが最後まで同じ型でなければならないことを意味します。この記事では単にstringを使用してきましたが、次の記事ではより有用なものに失敗の型を変更します。
まとめとガイドライン
Section titled “まとめとガイドライン”このシリーズの冒頭で、簡単に従えるレシピを提供すると約束しました。
しかし、今では少し圧倒されているかもしれません。物事をシンプルにする代わりに、より複雑にしてしまったように見えるかもしれません。同じことを行うたくさんの異なる方法を紹介しました!Bindと合成。Mapとswitch。どのアプローチを使うべきでしょうか?どの方法が最適でしょうか?
もちろん、すべてのシナリオに適した「正しい方法」は1つではありませんが、それでも約束通り、信頼性が高く繰り返し使える基本的なレシピとなるガイドラインをいくつか紹介します。
ガイドライン
- データフローの状況には、2線式の鉄道を基本モデルとして使用してください。
- ユースケースの各ステップに対して関数を作成してください。各ステップの関数は、さらに小さな関数から構築できます(例:検証関数)。
- 関数を接続するには、標準的な合成(
>>)を使用してください。 - フローに分岐器を挿入する必要がある場合は、
bindを使用してください。 - フローに1線式の関数を挿入する必要がある場合は、
mapを使用してください。 - フローに他の種類の関数を挿入する必要がある場合は、適切なアダプターブロックを作成して使用してください。
これらのガイドラインに従うと、特に簡潔でエレガントなコードにはならないかもしれません。しかし、一貫したモデルを使用することになり、メンテナンスが必要になったときに他の人にも理解しやすいはずです。
これらのガイドラインに従って、これまでの実装の主要部分を以下に示します。特に、最終的なusecase関数で>>がどこでも使用されていることに注目してください。
open RailwayCombinatorModule
let (&&&) v1 v2 = let addSuccess r1 r2 = r1 // 最初のものを返す let addFailure s1 s2 = s1 + "; " + s2 // 連結 plus addSuccess addFailure v1 v2
let combinedValidation = validate1 &&& validate2 &&& validate3
let canonicalizeEmail input = { input with email = input.email.Trim().ToLower() }
let updateDatabase input = () // 今はダミーのデッドエンド関数
// 例外を処理する新しい関数let updateDatebaseStep = tryCatch (tee updateDatabase) (fun ex -> ex.Message)
let usecase = combinedValidation >> map canonicalizeEmail >> bind updateDatebaseStep >> log最後に1つ提案があります。非専門家のチームと働いている場合、馴染みのない演算子記号は人々を戸惑わせる可能性があります。そこで、演算子に関するいくつかの追加ガイドラインを示します:
>>と|>以外の「奇妙な」演算子は使用しないでください。- 特に、全員が認識していない限り、
>>=や>=>のような演算子は使用しないでください。 - 例外として、モジュールや関数の先頭で演算子を定義する場合は使用しても構いません。たとえば、
&&&演算子を検証モジュールの先頭で定義し、その後そのモジュール内で使用することは可能です。
- この「鉄道指向」アプローチが気に入った場合、FizzBuzzに適用した例もご覧ください。
- このアプローチをさらに発展させる方法を示したスライドと動画もあります(いずれ、ブログ投稿として適切な形にする予定です)。
NDC Oslo 2014でこのトピックについて発表しました(画像をクリックすると動画が見られます)

そして、使用したスライドはこちらです: